2.3 HDFS HA 部署
2.3.1 硬件资源
部署 HA 集群, 要准备下面的硬件资源.
NameNode machines
2 台 NameNode machines, 一个用于运行 Active NameNode, 另外一个用于运行 Standby NameNode. 这个 2 台设备的硬件资源应该相等.
JournalNodes machines
用来运行 JournalNodes.
JournalNode 进程相对来说比较轻量级, 所以这些进程可以分配在其他的 Hadoop 设备上, 比如运行 NameNode, DataNode或者 Yarn ResourceManage的的设备上.
注意:
至少需要 3 个 JournalNode, 因为 edit log 的修改必须写到多个 JournalNode 上. 这样即使有一个 JournalNode 挂了, 其他的 2 个也可以工作.
为了提供更多的冗余, 也可以增加 JournalNode 的数量, 但是最好是奇数(3, 5, 7, ...). 因为只要不超过一半的 JournalNode 挂掉, 其他的仍然可以正常工作. 这个特性优点类似于前面学习的 Zookeeper.
还有一点需要注意:
在一个 HA 集群中, Standby NameNode 也会执行命名空间的检查点的, 所以没有必须再去运行一个 SecondaryNameNode.
事实上, 如果再运行 SecondaryNameNode 反而会出错.
2.3.2 配置
配置综述
在 HA 集群中, 所有的节点可以拥有相同的配置, 不需要根据节点的类型不同而添加不同的配置. 这给配置带来了很大的便利.
HA 集群使用 nameservice ID 标识一个 HDFS 实例, 而实际上, 他有可能包含多个 NameNode.
另外, 在 HA 集群中, 添加了一个新的抽象属性叫做 NameNode ID.
在集群中的每个不同的 NameNode 有一个不同 NameNode ID 来把他们区别开来.
为了让所有的设备可以使用相同的配置文件, 相关配置参数都会使用 nameserveice ID 和 NameNode ID 作为后缀.

配置细节
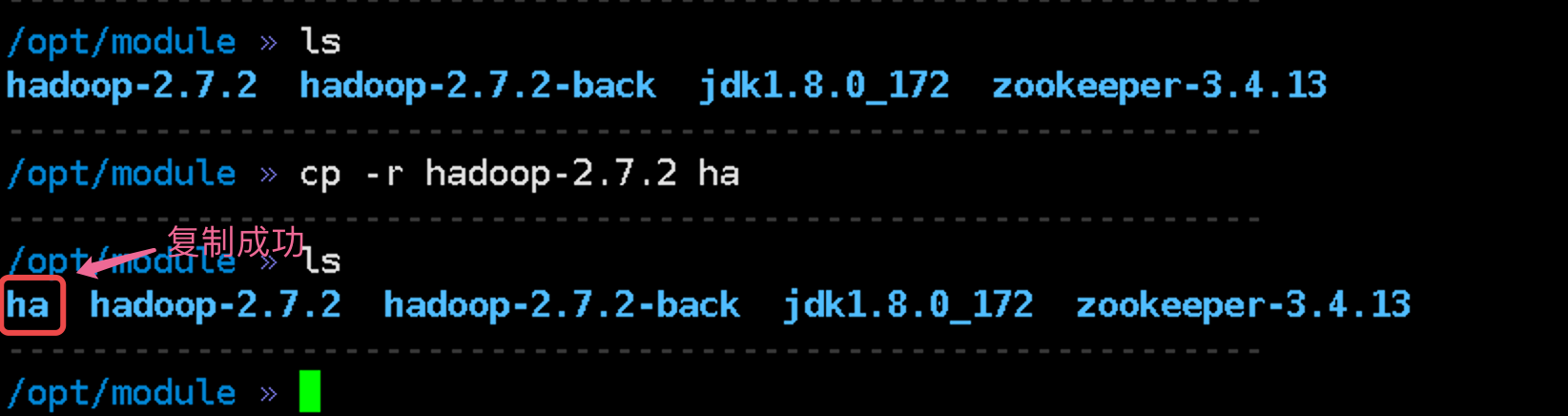
由于高可用后期学习期间使用较少, 所以我们把以前的 Hadoop 重新复制一份并命名 HA, 然后配置 HA 这个 Hadoop, 配置成功之后把他们分发到其他设备上.
注意:
- 这些配置的顺序并不重要.
配置 hdfs-site.xml
dfs.nameservices--- 新的名称服务器的逻辑名为这个名称服务选择一个逻辑名, 例如: mycluster. 并且这个值也会用在其他的配置选项中.
这个值是任意的, 但是他会用在其他配置和 HDFS 的绝对路径中.
<property> <name>dfs.nameservices</name> <value>mycluster</value> </property>
dfs.ha.namenodes.[nameservice ID]-- 给每个 NameNode 配置一个ID配置这个属性需要使用到
nameservce ID的值.这个属性的值是使用逗号隔开的多个
NameNode ID.如果你的
dfs.nameservices的值是mycluster, 想设置的NameNode ID的值分别是nn1, nn2, 则应该使用下面的设置:<property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property>注意:
- 目前每个集群最多可以设置 2 个 NameNode
dfs.namenode.rpc-address.[nameservice ID].[name node ID]--- 每个 NameNode 去监听的完整的 RPC 地址.每个 NameNode需要单独去配置.
<property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>hadoop201:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>hadoop203:8020</value> </property>
dfs.namenode.http-address.[nameservice ID].[name node ID]--- 每个 NameNode 去监听的 HTTP 地址. 可以通过这个地址在浏览器中查看 NameNode.<property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>hadoop201:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>hadoop203:50070</value> </property>
dfs.namenode.shared.edits.dir--- 一个URI, 用来标识 JNs 组它的值是有多个 JNs 的地址来组成. 每个之间用
;隔开.<property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop201:8485;hadoop202:8485;hadoop203:8485/mycluster</value> </property>
dfs.client.failover.proxy.provider.[nameservice ID]--- 一个 java 类, HDFS 客户端使用这个类与 Active NameNode 保持联系.配置一个类名就可以了. HDFS 客户使用这个类来检测哪个 NameNode 是活动的和哪个 NameNode 正在处理客户端的请求. 目前只有一个实现:
ConfiguredFailoverProxyProvider<property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property>
dfs.ha.fencing.methods--- 一个脚本或者 java 类的列表, 用来在备灾期间防护活动 NameNode.这个用来保证同一时刻只能有一个 Active NameNode.
有两种配置方法:
shell和sshfence. 二者选其一.shell<property> <name>dfs.ha.fencing.methods</name> <value>shell(/bin/true)</value> </property>说明:
- 其实使用任何一个 shell 命令都可以.
sshfence其实是通过 ssh 连接到 NameNode, 并杀死进程.
所以这种情况必须添加 ssh 免密登录.
<property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/atguigu/.ssh/id_rsa</value> </property>
dfs.journalnode.edits.dir--- JN 存储edits和 它的local state的路径必须是绝对路径.
<property> <name>dfs.journalnode.edits.dir</name> <value>/opt/module/ha/data/jn</value> </property>
关闭权限检查.
<property> <name>dfs.permissions.enable</name> <value>false</value> </property>
删除
SecondaryNameNode的设置.
配置 core-site.xml
fs.defaultFS<property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property>hadoop.tmp.dir--- 运行时产生的文件的目录最好配置到当前的 Hadoop 目录下.
<property> <name>hadoop.tmp.dir</name> <value>/opt/module/ha/data/tmp</value> </property>
部署细节
步骤1: 把配置的 hadoop 分发到其他设备上.
步骤2: 启动 JournalNode
如果前面所有的必须的配置完成, 必须还要首先启动 JournalNode
需要去每台设备上分别启动.
cd /opt/module/ha
./sbin/hadoop-daemon.sh start journalnode
注意:
- 由于
PATH中配置的是原来的 hadoop 的路径. 所以执行现在的命令的时候,必须先进入响应的路径之后, 再执行.
步骤3: 格式化 NameNode
在配置 NameNode 的设备中格式化其中 1 台.
注意: 一定还要先启动 JournalNode
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
注意:执行这些指令的是不要忘记 bin或者sbin
步骤4: copy NameNode 的元数据目录的内容
一旦格式化完成, 并且动了第一个 NameNode, 就需要把这个 NameNode 元数据目录的内容 copy到另外一台没有格式化的 NameNode 设备上.
在nn2上操作:
bin/hdfs namenode -bootstrapStandby
然后启动这个 NameNode
sbin/hadoop-daemon.sh start namenode
步骤5: 在 web 上显示这两个 NameNode 的状态.
http://hadoop201:50070/
http://hadoop203:50070/
注意: 目前还没有活动的 NameNode
步骤6: 在nn1上启动所有 DataNode
sbin/hadoop-daemons.sh start datanode

步骤7: 把 nn1 切换成 Active state
bin/hdfs haadmin -transitionToActive nn1