第 4 章 需求1: Top10 热门品类
创建离线子模块
创建子模块: sparkmall-offline
添加依赖
<dependencies>
<dependency>
<groupId>com.atguigu</groupId>
<artifactId>sparkmall-common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>=-098
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
</dependency>
</dependencies>
mysql 数据库准备
-- ----------------------------
-- create databse sparkmall
-- ----------------------------
drop database if EXISTS sparkmall;
create database sparkmall DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
-- ----------------------------
-- create table category_top10
-- ----------------------------
use sparkmall;
drop table if exists category_top10;
create table category_top10 (
taskId text,
category_id text,
click_count bigint(20) default null,
order_count bigint(20) default null,
pay_count bigint(20) default null
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
4.1 需求1: 简介
品类是指的产品的的分类, 一些电商品类分多级, 咱们的项目中品类类只有一级.
不同的公司可能对热门的定义不一样.
我们按照每个品类的
计算成功之后, 统计出来的数据存储到 Mysql 中.
4.2 需求1: 思路
思路1: 使用 sql 语句
分别统计每个品类点击的次数, 下单的次数和支付的次数.
1. categoryId => click_count
select count(*) where click not null group by click_category_id
2. ...
缺点: 统计三个指标就需要遍历三次整表, 相当耗时. 不可行.
思路2: 遍历一次, 统计出来三个指标
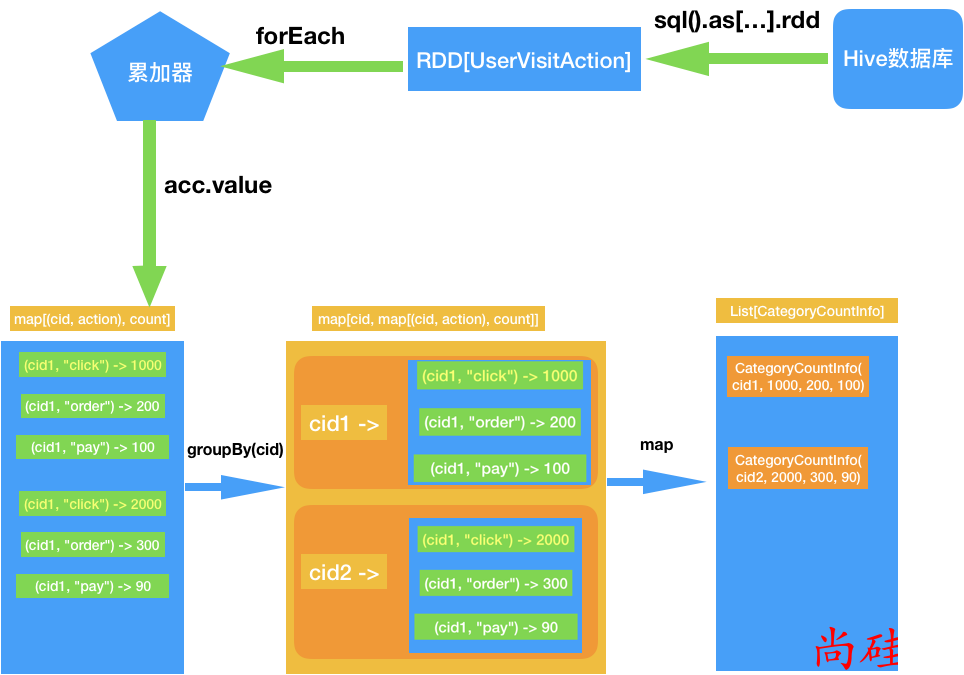
我们应该遍历一次数据, 就可以统计出来三个指标.
遍历全部日志表, 根据品类 id 和操作类型分别累加. 需要用到累加器
- 定义累加器
- 当碰到订单和支付业务的时候注意拆分字段才能得到品类 id
遍历完成之后就得到每个每个品类 id 和操作类型的数量.
按照点击下单支付的顺序来排序
取出 Top10
写入到 Mysql 数据库
4.3 需求1: 具体实现
1. 工具类
JDBCUtil.scala
这个类放在sparkmall-common 模块下
package com.atguigu.sparkmall.common.util
import java.util.Properties
import com.alibaba.druid.pool.DruidDataSourceFactory
object JDBCUtil {
val dataSource = initConnection()
/**
* 初始化的连接
*/
def initConnection() = {
val properties = new Properties()
val config = ConfigurationUtil("config.properties")
properties.setProperty("driverClassName", "com.mysql.jdbc.Driver")
properties.setProperty("url", config.getString("jdbc.url"))
properties.setProperty("username", config.getString("jdbc.user"))
properties.setProperty("password", config.getString("jdbc.password"))
properties.setProperty("maxActive", config.getString("jdbc.maxActive"))
DruidDataSourceFactory.createDataSource(properties)
}
/**
* 执行单条语句
*
* "insert into xxx values (?,?,?)"
*/
def executeUpdate(sql: String, args: Array[Any]) = {
val conn = dataSource.getConnection
conn.setAutoCommit(false)
val ps = conn.prepareStatement(sql)
if (args != null && args.length > 0) {
(0 until args.length).foreach {
i => ps.setObject(i + 1, args(i))
}
}
ps.executeUpdate
conn.commit()
}
/**
* 执行批处理
*/
def executeBatchUpdate(sql: String, argsList: Iterable[Array[Any]]) = {
val conn = dataSource.getConnection
conn.setAutoCommit(false)
val ps = conn.prepareStatement(sql)
argsList.foreach {
case args: Array[Any] => {
(0 until args.length).foreach {
i => ps.setObject(i + 1, args(i))
}
ps.addBatch()
}
}
ps.executeBatch()
conn.commit()
}
}
包对象 定义了判断字符串是否为空的方法
package com.atguigu.sparkmall
package object offline {
def isNotEmpty(text: String): Boolean = text != null && text.length == 0
def isEmpty(text: String): Boolean = !isNotEmpty(text)
}
2. bean 类
Condition用来封装从 hive 中读数据时的过滤条件
package com.atguigu.sparkmall.offline.bean
case class Condition(var startDate: String,
var endDate: String,
var startAge: Int,
var endAge: Int,
var professionals: String,
var city: String,
var gender: String,
var keywords: String,
var categoryIds: String,
var targetPageFlow: String)
CategoryCountInfo用来封装写入 Msyql 的数据.
package com.atguigu.sparkmall.offline.bean
case class CategoryCountInfo(taskId: String,
categoryId: String,
clickCount: Long,
orderCount: Long,
payCount: Long)
业务实现
1. 整个离线模块的入口类
OfflineApp.scala
package com.atguigu.sparkmall.offline
import java.util.UUID
import com.alibaba.fastjson.JSON
import com.atguigu.sparkmall.common.bean.UserVisitAction
import com.atguigu.sparkmall.common.util.ConfigurationUtil
import com.atguigu.sparkmall.offline.app.CategoryTop10App
import com.atguigu.sparkmall.offline.bean.Condition
import org.apache.spark.sql.SparkSession
object OfflineApp {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local[*]")
.appName("OfflineApp")
.enableHiveSupport()
.config("spark.sql.warehouse.dir", "hdfs://hadoop201:9000/user/hive/warehouse")
.getOrCreate()
val taskId = UUID.randomUUID().toString
// 根据条件过滤取出需要的 RDD, 过滤条件定义在配置文件中
val userVisitActionRDD = readUserVisitActionRDD(spark, readConditions)
println("任务1: 开始")
CategoryTop10App.statCategoryTop10(spark, userVisitActionRDD, taskId)
println("任务1: 结束")
}
/**
* 读取指定条件的 UserVisitActionRDD
*
* @param spark
* @param condition
*/
def readUserVisitActionRDD(spark: SparkSession, condition: Condition) = {
var sql = s"select v.* from user_visit_action v join user_info u on v.user_id=u.user_id where 1=1"
if (isNotEmpty(condition.startDate)) {
sql += s" and v.date>='${condition.startDate}'"
}
if (isNotEmpty(condition.endDate)) {
sql += s" and v.date<='${condition.endDate}'"
}
if (condition.startAge != 0) {
sql += s" and u.age>=${condition.startAge}"
}
if (condition.endAge != 0) {
sql += s" and u.age<=${condition.endAge}"
}
import spark.implicits._
spark.sql("use sparkmall")
spark.sql(sql).as[UserVisitAction].rdd
}
/**
* 读取过滤条件
*
* @return
*/
def readConditions: Condition = {
// 读取配置文件
val config = ConfigurationUtil("conditions.properties")
// 读取到其中的 JSON 字符串
val conditionString = config.getString("condition.params.json")
// 解析成 Condition 对象
JSON.parseObject(conditionString, classOf[Condition])
}
}
2. 用到的 Map 累加器
package com.atguigu.sparkmall.offline.acc
import org.apache.spark.util.AccumulatorV2
import scala.collection.mutable
class MapAccumulator extends AccumulatorV2[(String, String), mutable.Map[(String, String), Long]] {
val map = mutable.Map[(String, String), Long]()
override def isZero: Boolean = map.isEmpty
override def copy(): AccumulatorV2[(String, String), mutable.Map[(String, String), Long]] = {
val newAcc = new MapAccumulator
map.synchronized {
newAcc.map ++= map
}
newAcc
}
override def reset(): Unit = map.clear
override def add(v: (String, String)): Unit = {
map(v) = map.getOrElseUpdate(v, 0) + 1
}
// otherMap: (1, click) -> 20 this: (1, click) -> 10 thisMap: (1,2) -> 30
// otherMap: (1, order) -> 5 thisMap: (1,3) -> 5
override def merge(other: AccumulatorV2[(String, String), mutable.Map[(String, String), Long]]): Unit = {
val otherMap: mutable.Map[(String, String), Long] = other.value
otherMap.foreach {
kv => map.put(kv._1, map.getOrElse(kv._1, 0L) + kv._2)
}
}
override def value: mutable.Map[(String, String), Long] = map
}
3. 需求1具体实现
package com.atguigu.sparkmall.offline.app
import com.atguigu.sparkmall.common.bean.UserVisitAction
import com.atguigu.sparkmall.common.util.JDBCUtil
import com.atguigu.sparkmall.offline.acc.MapAccumulator
import com.atguigu.sparkmall.offline.bean.CategoryCountInfo
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object CategoryTop10App {
// 统计热门品 Top10
def statCategoryTop10(spark: SparkSession, userVisitActionRDD: RDD[UserVisitAction], taskId: String) = {
// 1. 注册累加器
val acc = new MapAccumulator
spark.sparkContext.register(acc, "CategoryActionAcc")
// 2. 遍历日志
userVisitActionRDD.foreach {
visitAction => {
if (visitAction.click_category_id != -1) {
acc.add(visitAction.click_category_id.toString, "click")
} else if (visitAction.order_category_ids != null) {
visitAction.order_category_ids.split(",").foreach {
oid => acc.add(oid, "order")
}
} else if (visitAction.pay_category_ids != null) {
visitAction.pay_category_ids.split(",").foreach {
pid => acc.add(pid, "pay")
}
}
}
}
// 3. 遍历完成之后就得到每个每个品类 id 和操作类型的数量. 然后按照 CategoryId 进行进行分组
val actionCountByCategoryIdMap = acc.value.groupBy(_._1._1)
// 4. 聚合成 CategoryCountInfo 类型的集合
val categoryCountInfoList = actionCountByCategoryIdMap.map {
case (cid, actionMap) => CategoryCountInfo(
taskId,
cid,
actionMap.getOrElse((cid, "click"), 0),
actionMap.getOrElse((cid, "order"), 0),
actionMap.getOrElse((cid, "pay"), 0)
)
}.toList
// 5. 按照 点击 下单 支付 的顺序降序来排序
val sortedCategoryInfoList = categoryCountInfoList.sortBy(info => (info.clickCount, info.orderCount, info.payCount))(Ordering.Tuple3(Ordering.Long.reverse, Ordering.Long.reverse, Ordering.Long.reverse))
// 6. 截取前 10
val top10 = sortedCategoryInfoList.take(10)
// 7. 插入数据库
val argsList = top10.map(info => Array(info.taskId, info.categoryId, info.clickCount, info.orderCount, info.payCount))
JDBCUtil.executeBatchUpdate("insert into category_top10 values(?, ?, ?, ?, ?)", argsList)
}
}
/*
1. 遍历全部日志表, 根据品类 id 和操作类型分别累加. 需要用到累加器
- 定义累加器
累加器用什么来保存? map
key: (categoryId, action) 元组来表示
value: count
- 当碰到订单和支付业务的时候注意拆分字段才能得到品类 id
2. 遍历完成之后就得到每个每个品类 id 和操作类型的数量. 然后按照 cid 进行聚合, 聚合成 CategoryCountInfo 类型
3. 按照 点击 下单 支付 的顺序来排序
4. 取出 Top10
5. 写入到 Mysql 数据库
*/