3.2.4.2 使用协处理器写入被叫信息
我们还可以使用协处理的方式来写入被叫信息.
在 HBase 中类似关系数据库中的存储过程和触发器的功能,
它叫协处理器(coprocessor)
在 0.92 之前,HBase 还没有协处理器,那个时候就算简单的统计表有多少行的任务都需要将服务端的数据全部取出来挨个地在客户端进行统计,可以想象这样做的性能之低下。
所以在 0.92 之后 HBase 加入了协 处理器,以便于用户可以扩展服务端的类库,并直接在服务端完成特定任务而不需要跟客户端之间有 IO 操作。
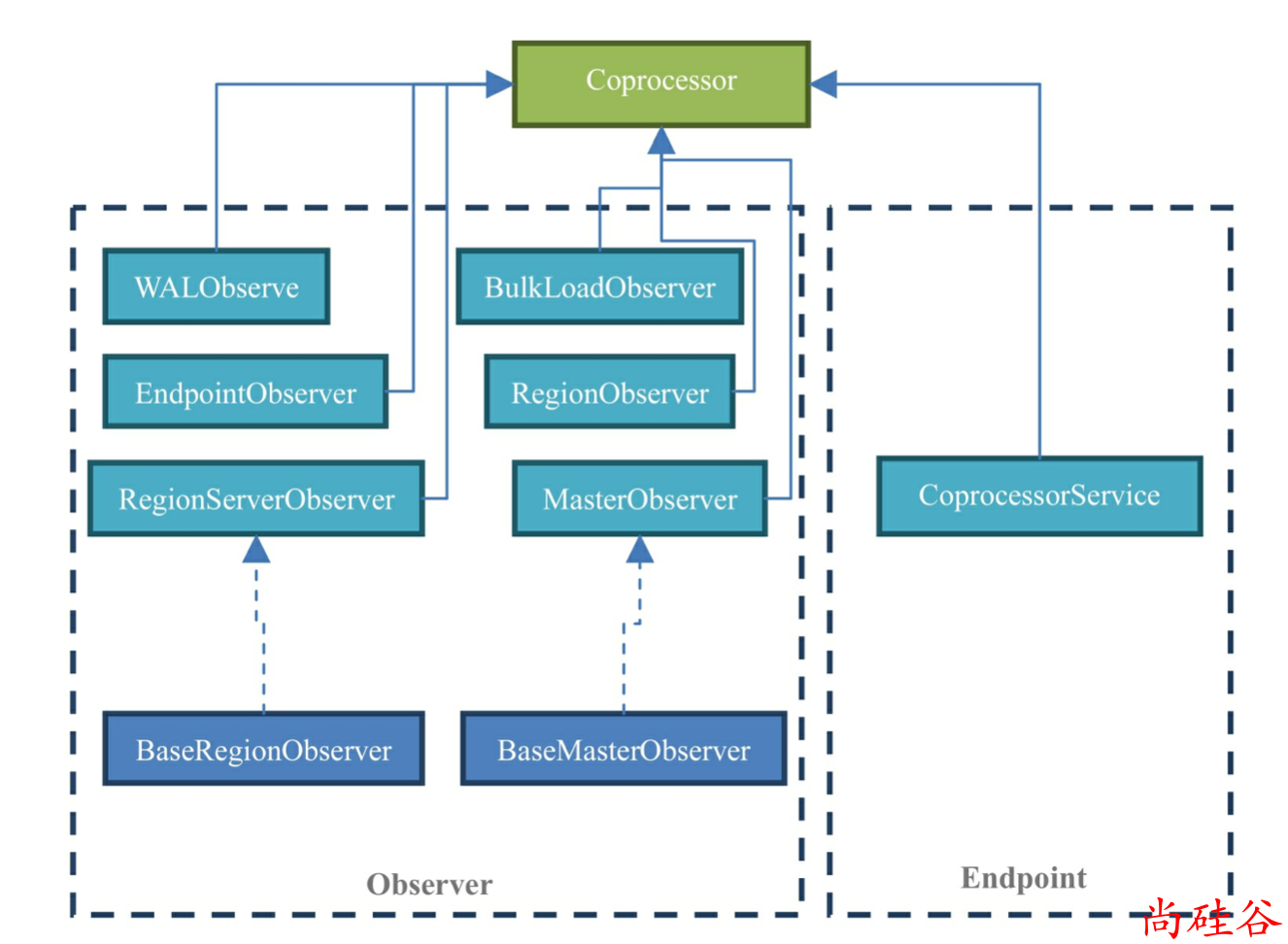
协处理器是运行在服务端的程序.
由于协处理是运行在服务器端的, 所以需要添加依赖:
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.2.1</version>
</dependency>
如果已经添加, 就忽略.
1. 创建协处理器类: CalleeWriteObserver
package com.atguigu.dataconsumer.coprocessor;
import com.atguigu.dataconsumer.HBaseDao;
import org.apache.hadoop.hbase.client.Durability;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.regionserver.wal.WALEdit;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class CalleeWriteObserver extends BaseRegionObserver {
// 创建 HBaseDao 对象
private HBaseDao hBaseDao = new HBaseDao();
/**
* 覆写 postPut 方法, put 方法执行完毕之后执行此方法
* <p>
* 当插入一条主叫记录之后, 再这里再插入一条被叫记录
* <p>
* 由于插入被叫信息也是会执行 put 方法, 所以会再次出发这个方法, 一定要防止死循环.
*
* @param e
* @param put
* @param edit
* @param durability
* @throws IOException
*/
@Override
public void postPut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability) throws IOException {
// 插入主叫数据时的行 0000_16480981069_2018-02-24 04:59:34_19877232369_1600_0
String row = Bytes.toString(put.getRow());
// 组装成这样的字符串 19877232369,2018-02-24 04:59:34,16480981069,1600,1
String[] split = row.split("_");
if ("1".equals(split[5])) return; // 如果插入的是被叫信息, 则直接返回不做任何操作.
String value = split[3] + "," + split[2] + "," + split[1] + "," + split[4] + ",1";
hBaseDao.put(value);
}
}
2. 如何加载协处理
加载协处理的方式一般有 3 种:
通过 API 的方式加载
针对某个表
配置文件
hive-site.xml加载针对所有表
shell 的方式加载
前两种比较常用, 第三种不常用.
3. 通过 API 的方式加载协处理器
今天我们选择使用 API 的方式来加载协处理器.
需要重新创建表, 并在表描述器中来注册协处理器.
需要先删除原来的表(使用 shell 手动删除即可)
desc.addCoprocessor("com.atguigu.dataconsumer.coprocessor.CalleeWriteObserver");
4. 把包含协处理的项目打 jar 包之后, 放入 $HBASE_HOME/lib 目录下
注意需要分发到集群中的每个 RegionServer 中.
5. 重启 HBase 服务器
7. 启动消费者, 开始向 HBase 插入数据
8. 确认数据是否插入成功.
使用配置文件的方式注册协处理器
在hbase-site.xml下添加如下属性:
<property>
<name>hbase.coprocessor.region.classes</name>
<value>com.atguigu.dataconsumer.coprocessor.CalleeWriteObserver</value>
</property>
分发配置文件, 重启 HBase.
注意:
由于配置文件的方式是对所有表有效, 所以需要在协处理中对表做判断, 否则协处理没有办法正常工作
使用了配置文件注册, 就不需要再使用 API 的方式注册添加了
不管哪种方式添加, 都需要把 jar 包放入
$HBASE_HOME/lib目录下.