5.1 本地运行模式
本地运行模式不需要额外的设置. 只需要执行相应的jar包就可以了.
不需要任何的集群配置, 本地运行模式其实也是一种单节点模式.
Hadoop提供了两个案例, 我们执行这两个案例.
5.1.1 官方 grep 案例
这个案例是提供一些文本文件, grep可以从中找到想要匹配的文本(可以是正则表达式).
进入
Hadoop的安装目录cd /opt/module/hadoop-2.7.2
在当前目录下创建目录
input. 这个文件夹将来用来存放要统计的文本文件.mkdir input把
etc/hadoop下的所有xml文件copy到input目录下. 这些xml就是我们要统计的文本cp etc/hadoop/*.xml input
查看
input文件中是否有文件.cd input ls
执行
share目录下MapReduce程序hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
进入
output查看输出结果

5.1.2 官方wordcount案例
这个案例用来统计文本中每个单词出现的次数.
统计结果按照单词在字典中的排序来输出.
输入数据仍然使用刚才的那些
xml文件.执行程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount input out1
进入
out1查看输出结果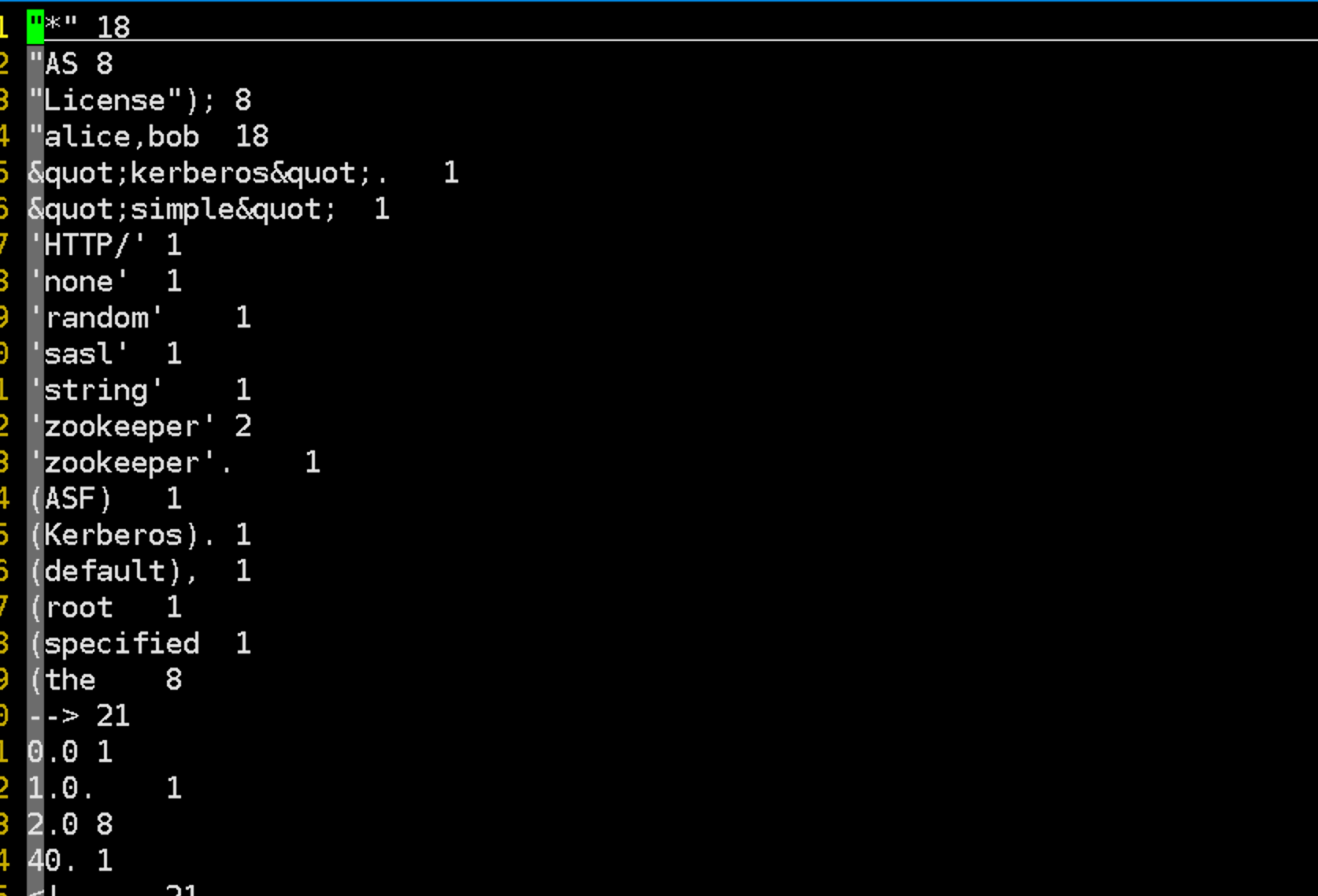
注意:
- 如果出现执行失败的情况下, 请确认
jdk和hadoop环境变量是否配置成功.