9.2 预分区
9.2.1 Region 为什么要拆分
一个Region就是一个表的一段 Rowkey 的数据集合。当 Region 太大的时候HBase 会拆分它。
为什么要拆分呢?
因为当某个 Region 太大的时候读取效率太低了。
大家可以想想我们 为什么从 MySQL、Oracle 转移到 NoSQL 来?
最根本的原因就是这些关系型数据库把数据放到一个地方,查询的本质其实也就是遍历 key;
而当数据增大到上亿的时候同一个磁盘已经无法应付这些数据的读取了,因为遍历一遍数据的时间实在太长了。
我们用 NoSQL 的理由就是其能把大数据分拆到不同的机器上,然后就像查询一个完整的数据一样查询他们。
但是当你的 Region 太大的时候,此时这个 Region 一样会遇到跟传统关系 型数据库一样的问题,所以 HBase 会拆分 Region。
这也是 HBase 的一个优点,有些人会介绍 HBase 为“一个会自动分片的数据库”。
9.2.2 自动拆分
自动拆分采用不同的策略.
0.94 版本之前采用的是 ConstantSizeRegionSplitPolicy 策略。
这个策略非常简单,从名字上就可以看出这个策 略就是按照固定大小来拆分Region。它唯一用到的参数是: hbase.hregion.max.filesize, 默认值是 10G, 也就是当 Region 的大小达到 10G 的时候, 会自动拆分成两个 Region.
0.94 版本之后就不用这种策略了.
0.94 版本之后,有了 IncreasingToUpperBoundRegionSplitPolicy 策略。并且默认使用的这种策略.
这种策略从名字上就可以看出是限制不断增长的文件尺寸的策略。
我们以前使用传统关系型数据库的时候或许有这样的经验,有的数据库的文件增长是翻倍增长的,比如第一个文件是64MB,第二个就是 128MB,第三个就是256MB。
HBase 这种策略就是模仿此类情况来实现的。
文件尺寸限制是动态的,依赖以下公式来计算:

说明:
tableRegionCount:表在这个 RegionServer 上这个表所拥有的 Region 数量总和。initialSize:如果你定义了hbase.increasing.policy.initial.size,则使用这个数值;如果没有定义,就用 memstore 的刷写大小的2倍,即hbase.hregion.memstore.flush.size * 2。defaultRegionMaxFileSize:ConstantSizeRegionSplitPolicy所用到的hbase.hregion.max.filesize,即 Region 最大大小。Math.min:取这两个数值的最小值。
假如hbase.hregion.memstore.flush.size定义为128MB,那么文件 尺寸的上限增长将是这样:
(1)刚开始只有 1 个文件的时候,上限是256MB,因为1^3 * 128*2 = 256MB。
(2)当有 2 个文件的时候,上限是2GB,因为2^3 * 128 * 2 = 2048MB。
(3)当有 3 个文件的时候,上限是6.75GB,因为3^3 * 128 * 2 = 6912MB。
(4)以此类推,直到计算出来的上限达到 hbase.hregion.max.filesize region 所定义的10GB。
还有一些其他的分区策略, 在这里不做介绍.
9.2.2 预分区
每一个 region 维护着 startRow 与 endRowKey,如果加入的数据符合某个region 维护的 rowKey 范围,则该数据交给这个 region 维护。
那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高HBase 性能。
有几种预分区的方式:
1. 手动设定分区点
create 'staff1','info','partition1',SPLITS =>['1000','2000','3000','4000']

2. 生成16进制序列预分区
create 'staff2','info','partition2',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
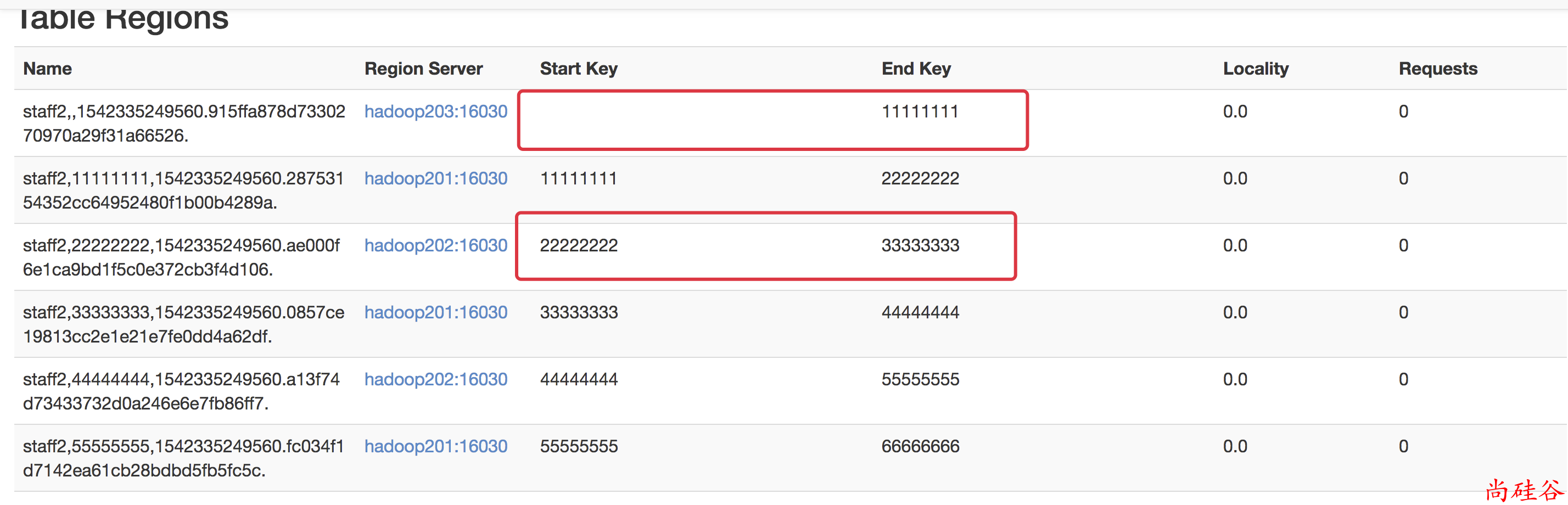
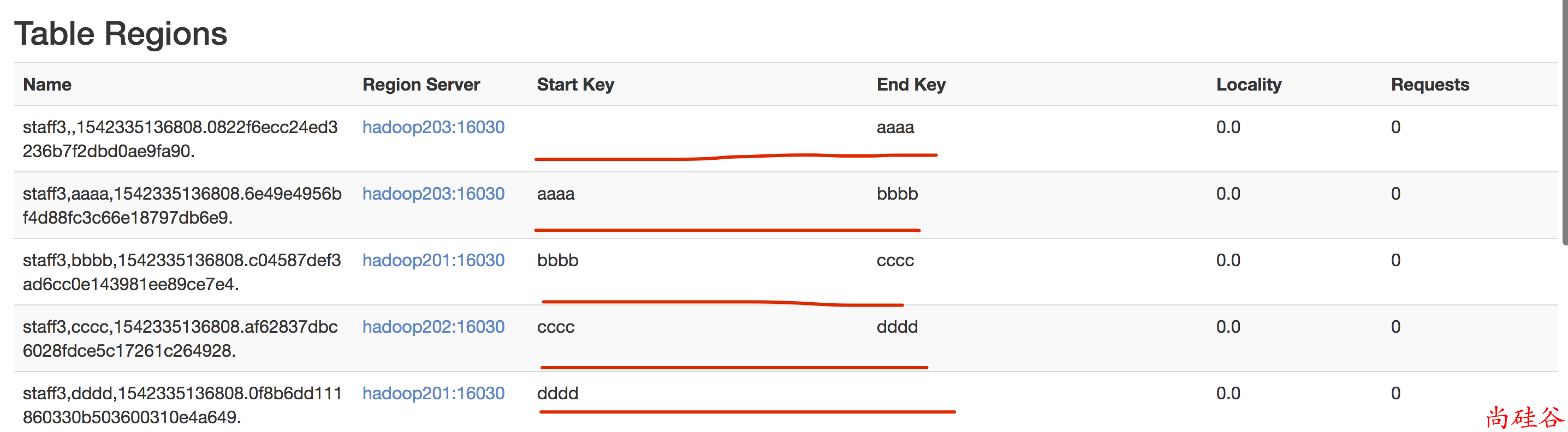
3. 按照文件中设置的规则预分区
创建splits.txt文件内容如下:
aaaa
bbbb
cccc
dddd
然后执行:
create 'staff3','partition3',SPLITS_FILE => 'splits.txt'
4. 使用 JavaAPI 创建预分区
//自定义算法,产生一系列Hash散列值存储在二维数组中
byte[][] splitKeys = 某个散列值函数
//创建HBaseAdmin实例
HBaseAdmin hAdmin = new HBaseAdmin(HBaseConfiguration.create());
//创建HTableDescriptor实例
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
//通过HTableDescriptor实例和散列值二维数组创建带有预分区的HBase表
hAdmin.createTable(tableDesc, splitKeys);
例如:
public static void customSplitRegion(String tableName, String f1) throws IOException {
if (isTableExists(tableName)) return;
HTableDescriptor desc = new HTableDescriptor(TableName.valueOf(tableName));
desc.addFamily(new HColumnDescriptor(f1));
byte[][] keys = {
Bytes.toBytes("aa"),
Bytes.toBytes("bb"),
Bytes.toBytes("cc"),
Bytes.toBytes("dd"),
};
admin.createTable(desc, keys);
}
