3.4 Kafka 消费过程分析
3.4.1 消费者和消费者群组
假设我们有一个应用程序需要从一个 Kafka 主题读取消息井验证这些消息,然后再把它们保存起来。
应用程序需要创建一个消费者对象,订阅主题并开始接收消息,然后验证消息井保存结果。
过了一阵子, 生产者往主题写入消息的速度超过了应用程序验证数据的速度,这个时候该怎么办?如果只使用单个消费者处理消息, 应用程序会远跟不上消息生成的速度。 显然, 此时很有必要对消费者进行横向伸缩。 就像多个生产者可以向相同的主题写入消息一样, 我们也可以使用多个消费者从同一个主题读取消息,对消息进行分流。
这样多个消费者从同一个主体读取消息, 就组成了消费者组.
Kafka 消费者从属于消费者群组。
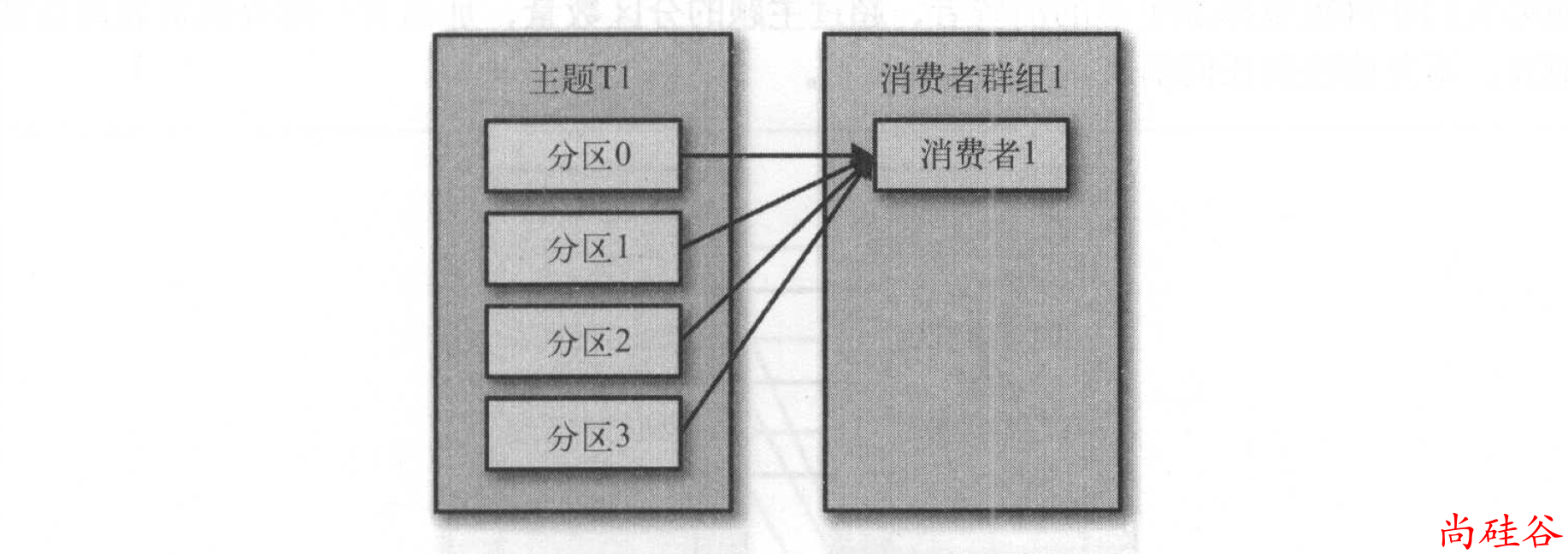
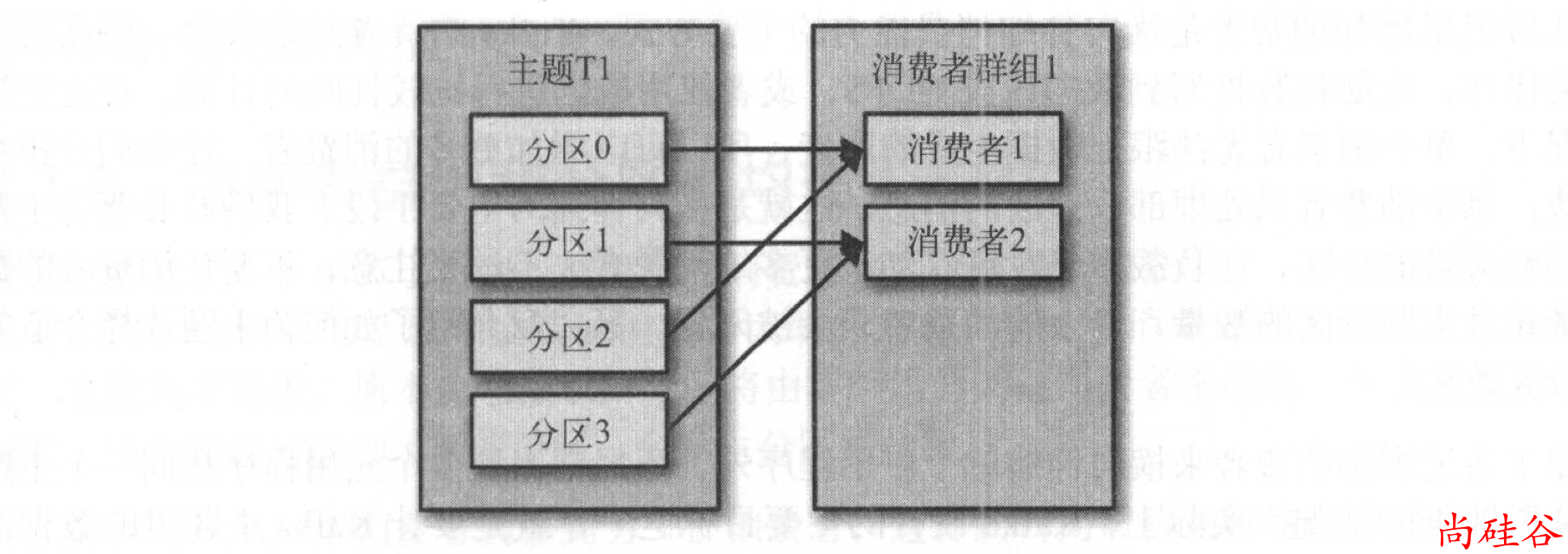
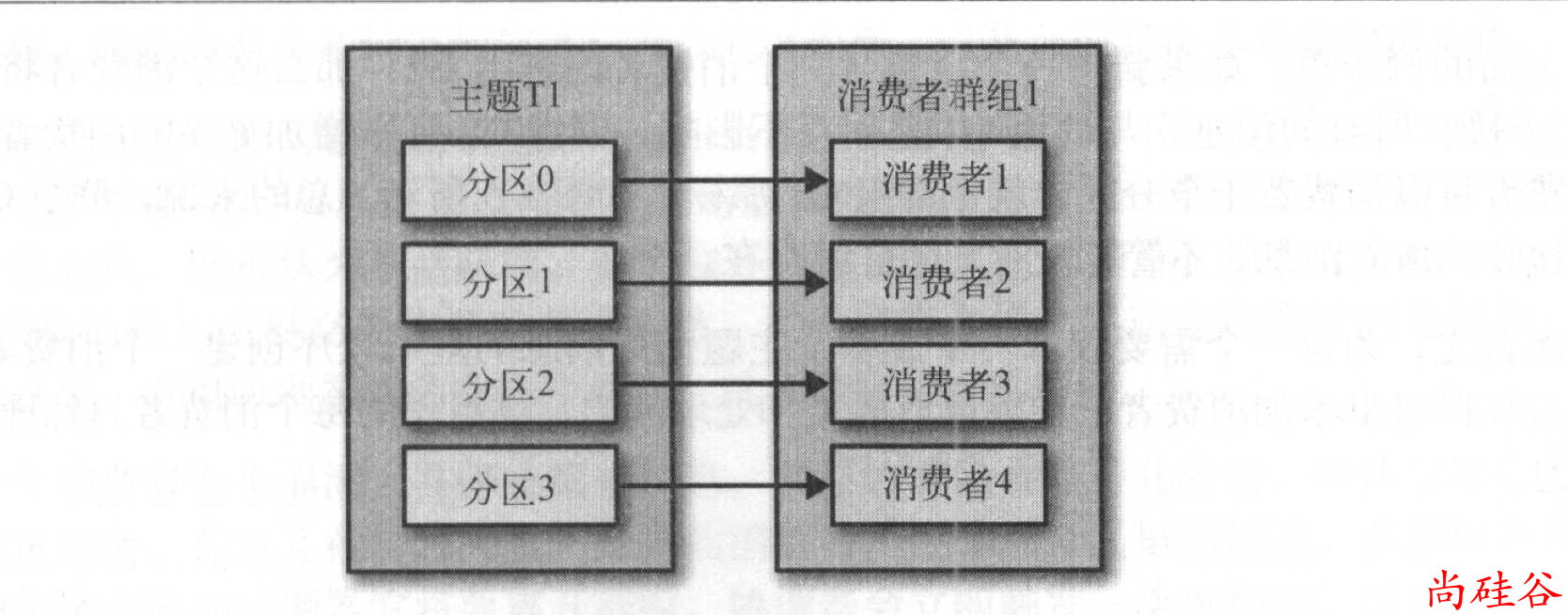
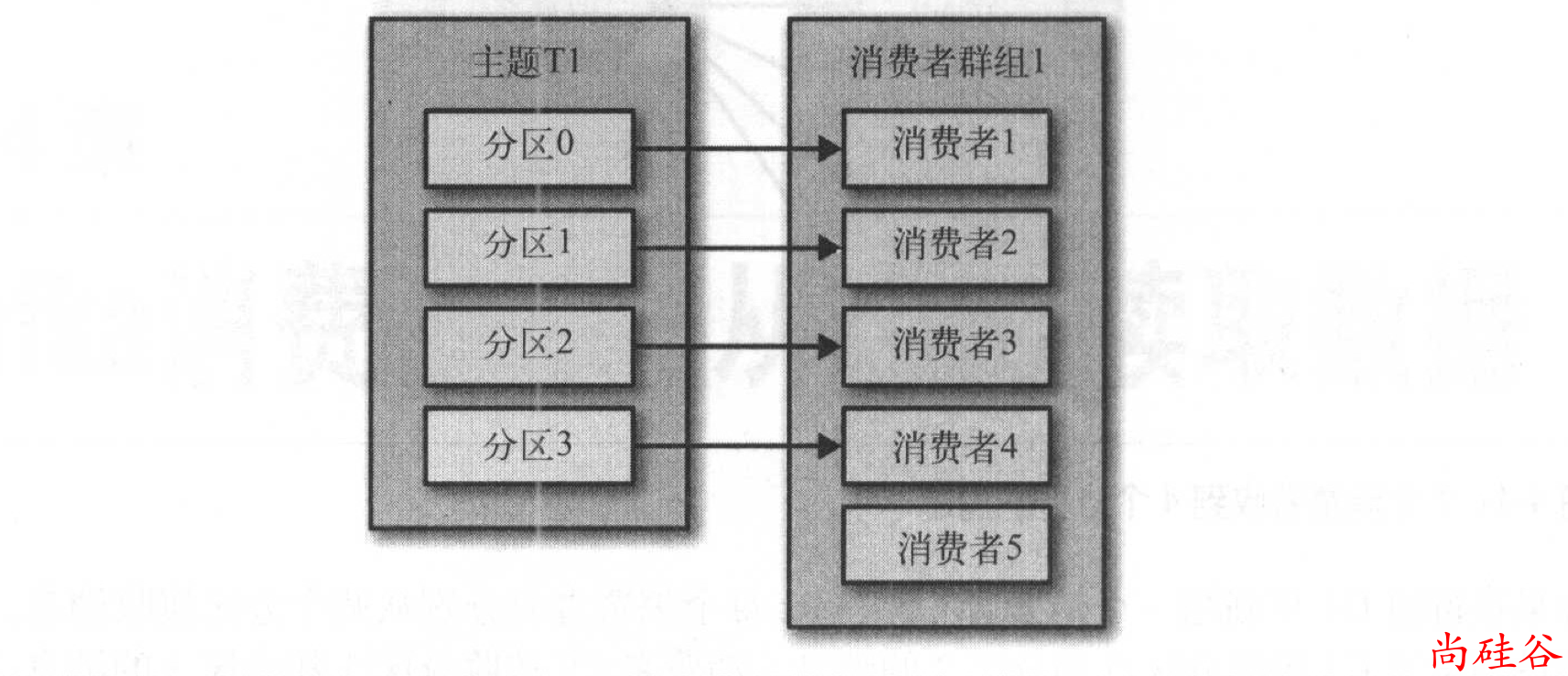
往群组里增加消费者是横向伸缩消费能力的主要方式。
Kafka 消费者经常会做一些高延迟的操作,比如把数据写到数据库或 HDFS,或者使用数据进行比较耗时的计算。在这些情况下,单个消费者无法跟上数据生成的速度,所以可以增加更多的消费者,让它们分担负载,每个消费者只处理部分分区的消息,这就是横向伸缩的主要手段。
我们有必要为主题创建大量的分区,在负载增长时可以加入更多的消费者。不过要注意,
不同于传统的消息系统,横向伸缩 Kafka 消费者和消费者群组并不会对性能造成负面影响。
当然也可以多个消费者群组消费同一个主题:
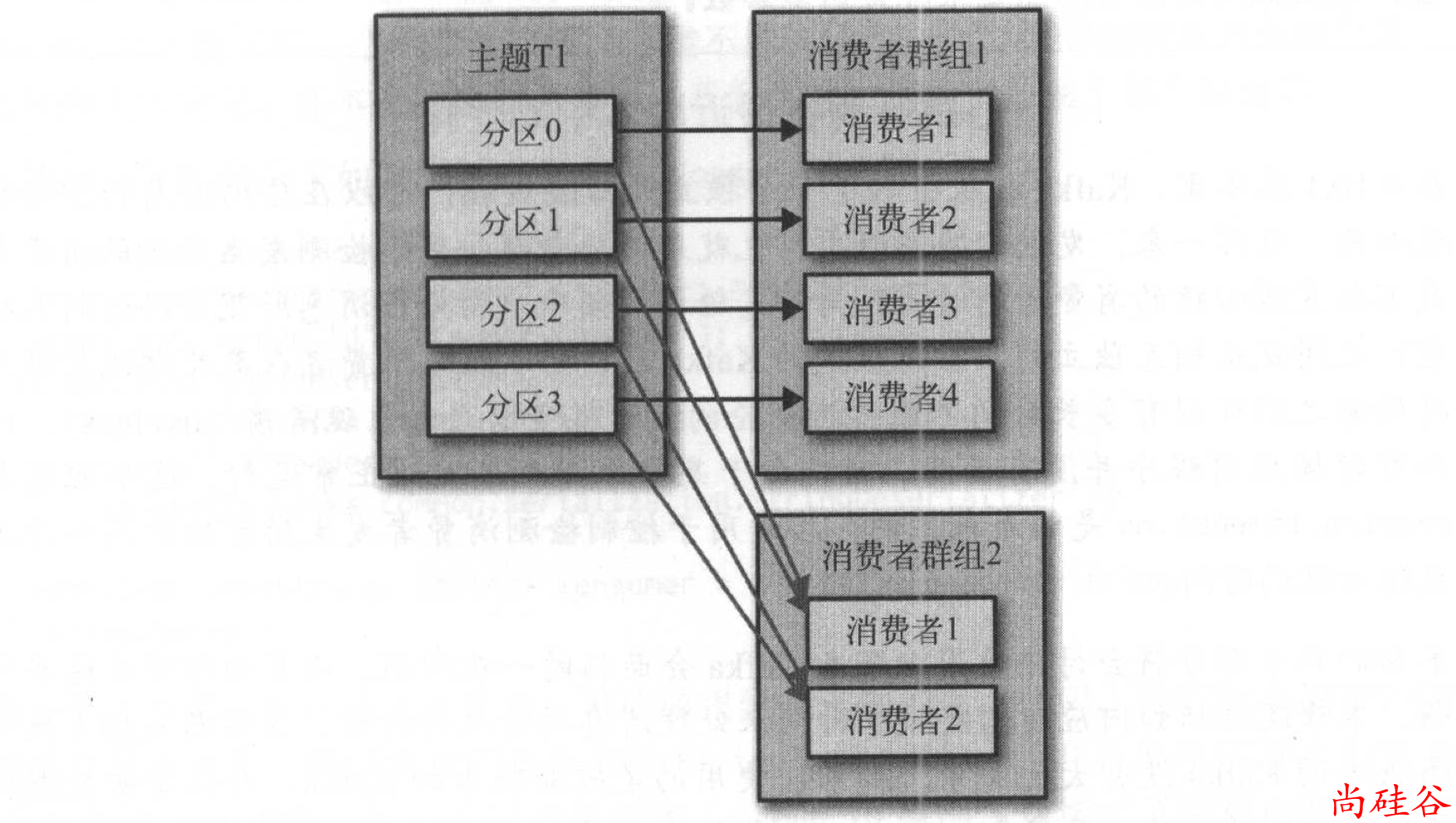
3.4.2 消费者群组和分区再平衡
群组里的消费者 共同读取主题的分区。
一个新的悄费者加入群组时,它读取的是原本由其他消费者读取的消息。
当一个消费者被关闭或发生崩愤时,它就离开群组,原本由它读取的分区将由群组里的其他消费者来读取。
在主题发生变化时,比如管理员添加了新的分区, 会发生分区重分配。
分区的所有权从一个消费者转移到另一个消费者,这样的行为被称为再均衡。
再均衡非常重要,它为消费者群组带来了高可用性和伸缩性.
3.4.3 消费方式
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成 consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而 pull 模式则可以根据 consumer 的消费能力以适当的速率消费消息。
对于Kafka而言,pull 模式更合适,它可简化 broker 的设计,consumer 可自主控制消费消息的速率,同时 consumer 可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
pull 模式不足之处是,如果 kafka 没有数据,消费者可能会陷入循环中,一直等待数据到达。为了避免这种情况,我们在我们的拉请求中有参数,允许消费者请求在等待数据到达的“长轮询”中进行阻塞(并且可选地等待到给定的字节数,以确保大的传输大小)