13.1 思路分析
数据存储在哪里?
1. redis: 交互性能好, 但是不能做聚合
2. hbase: 交互新能向可, 无法做分析聚合
3. hive: 可以分析聚合, 但是交互性能差
4. mysql: 交互性能好, 可以分析聚合, 但是数量大的时候撑不住
- ES: 交互性能好, 能分析聚合, 支持大数据量, 唯一的缺陷: 不能多表 join
所以我们使用 ES 来存储我们的数据!
ES 中的数据来自哪里?
有 2 部分来源:
T+1 数据(离线数据)一般来源于数仓
T+0 的数据(实时数据)一般来源于 Mysql
T+1 的数据又来源于数仓的哪一层
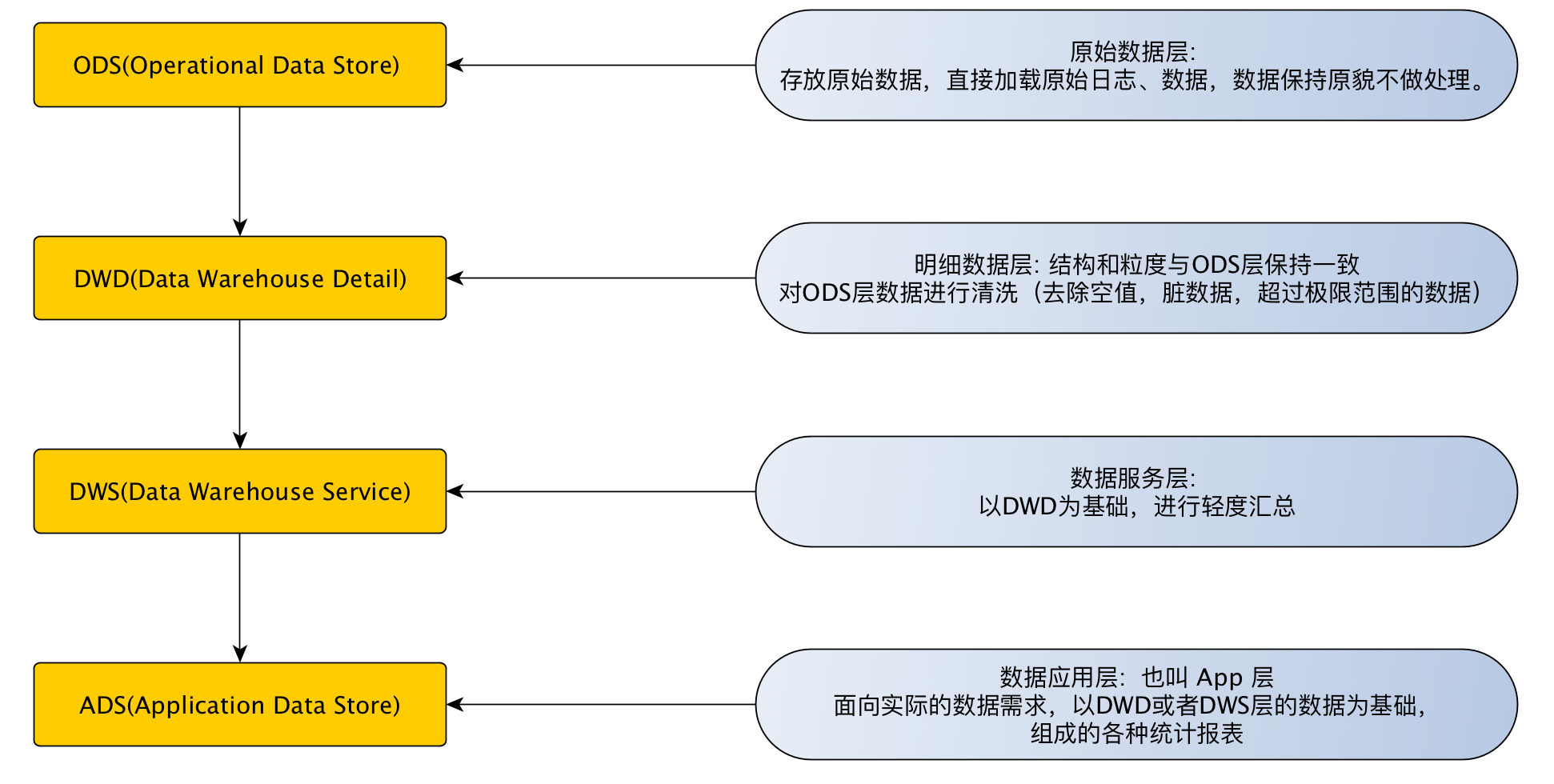
由于 ES 的数据需要明细, 并且自己还没有 join 的功能, 所以应该从 DWS 层获取数据.
通过 SparkSql 把数据存入到 ES 中
T+0 的数据怎么读
mysql -> Canal -> kafka -> SparkStreaming -> ES
但是这里有一个问题, Canal 获取到数据是一个表一个表的, 但是 ES 需要的是宽表数据, 怎么解决这个问题?
企业通常的做法: Canal 获取到一条数据之后, 再去反查 Mysql, 把信息给补全了, 然后再把相当于宽表的一条数据集存储到 Kafka 中.
在课堂上, 我们只处理 T+1 的数据, 没有处理 T+0的数据.