第 2 章 架构分析
2.1 T+1 数据(离线数据)
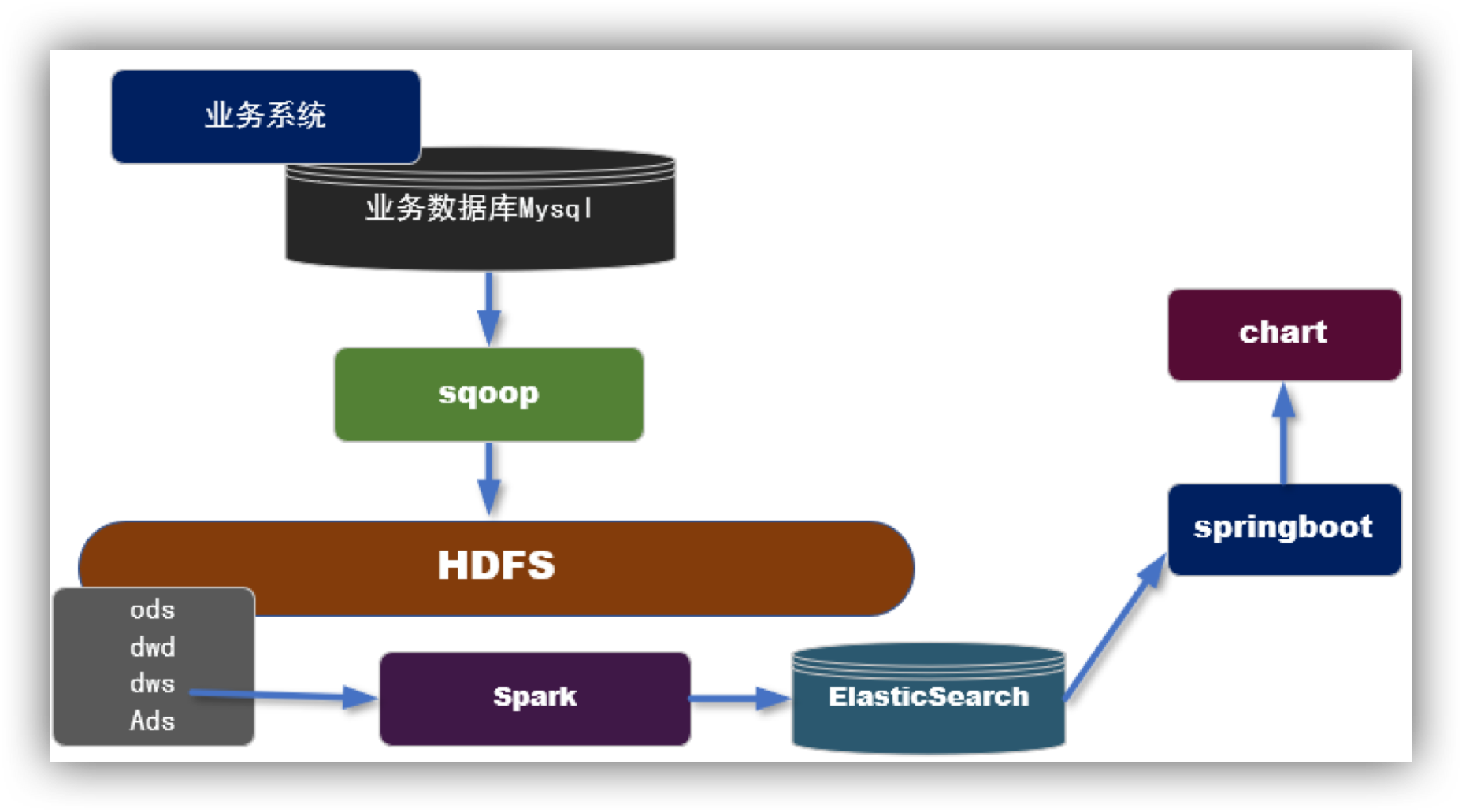
实现步骤
- 利用sqoop等工具,从业务数据库中批量抽取数据
- 利用数仓作业,在dws层组织宽表(用户购买行为)
- 开发spark的批处理任务,把dws层的宽表导入到ES中
- 从ES读取数据发布接口,对接可视化模块。
特点
- 优点: 可以利用在离线作业处理好的dws层宽表,直接导出一份到ES进行快速交互的分析。
- 缺点: 因为要用离线处理的后的结果在放入ES,所以时效性等同于离线数据
2.2 T+0 数据(实时数据)
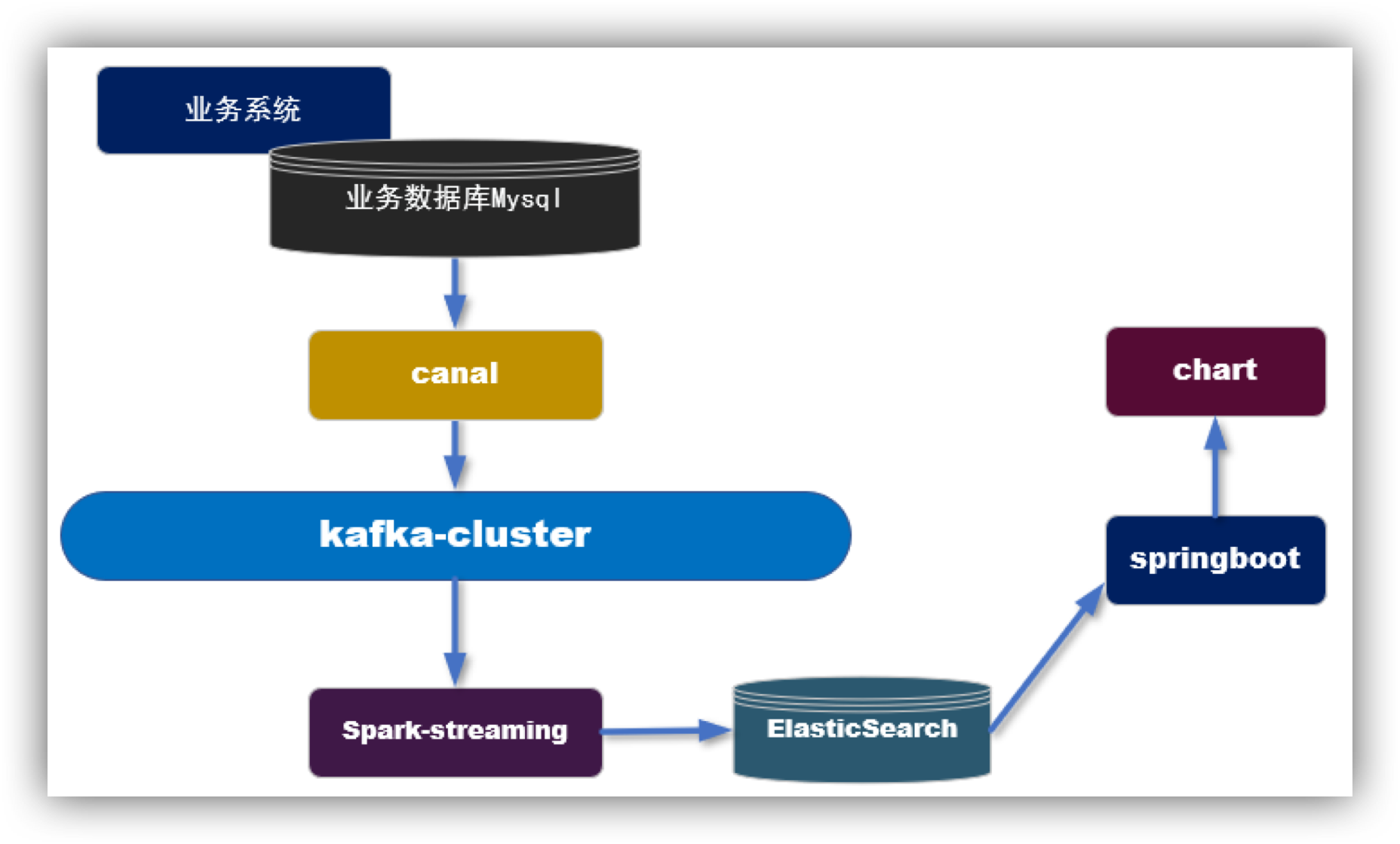
实现步骤
- 利用canal抓取对应的数据表的实时新增变化数据,推送到Kafka
- 在 spark-streaming 中进行转换,过滤,关联组合成宽表的结构。
- 保存到ES中
- 从ES读取数据发布接口,对接可视化模块。
特点
优点: 实时产生数据,时效性非常高。 缺点: 因为从 kafka 中得到的是原始数据,所以要利用spark-streaming要进行加工处理,相对来说要比批处理方式麻烦,比如join操作。