5.3.3 Key-Value 类型--1
大多数的 Spark 操作可以用在任意类型的 RDD 上, 但是有一些比较特殊的操作只能用在key-value类型的 RDD 上.
这些特殊操作大多都涉及到 shuffle 操作, 比如: 按照 key 分组(group), 聚集(aggregate)等.
在 Spark 中, 这些操作在包含对偶类型(Tuple2)的 RDD 上自动可用(通过隐式转换).
object RDD {
implicit def rddToPairRDDFunctions[K, V](rdd: RDD[(K, V)])
(implicit kt: ClassTag[K], vt: ClassTag[V], ord: Ordering[K] = null): PairRDDFunctions[K, V] = {
new PairRDDFunctions(rdd)
}
键值对的操作是定义在PairRDDFunctions类上, 这个类是对RDD[(K, V)]的装饰.
1. partitionBy
作用: 对 pairRDD 进行分区操作,如果原有的 partionRDD 的分区器和传入的分区器相同, 则返回原 pairRDD,否则会生成 ShuffleRDD,即会产生 shuffle 过程。
partitionBy 算子源码
def partitionBy(partitioner: Partitioner): RDD[(K, V)] = self.withScope {
if (self.partitioner == Some(partitioner)) {
self
} else {
new ShuffledRDD[K, V, V](self, partitioner)
}
}
scala> val rdd1 = sc.parallelize(Array((1, "a"), (2, "b"), (3, "c"), (4, "d")))
rdd1: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd1.partitions.length
res1: Int = 2
scala> rdd1.partitionBy(new org.apache.spark.HashPartitioner(3)).partitions.length
res3: Int = 3
2. reduceByKey(func, [numTasks])
作用: 在一个(K,V)的 RDD 上调用,返回一个(K,V)的 RDD,使用指定的reduce函数,将相同key的value聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置。
scala> val rdd1 = sc.parallelize(List(("female",1),("male",5),("female",5),("male",2)))
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd1.reduceByKey(_ + _)
res1: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[1] at reduceByKey at <console>:27
scala> res1.collect
res2: Array[(String, Int)] = Array((female,6), (male,7))
3. groupByKey()
作用: 按照key进行分组.
scala> val rdd1 = sc.parallelize(Array("hello", "world", "atguigu", "hello", "are", "go"))
rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[2] at parallelize at <console>:24
scala> val rdd2 = rdd1.map((_, 1))
rdd2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at <console>:26
scala> rdd2.groupByKey()
res3: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[4] at groupByKey at <console>:29
scala> res3.collect
res4: Array[(String, Iterable[Int])] = Array((are,CompactBuffer(1)), (hello,CompactBuffer(1, 1)), (go,CompactBuffer(1)), (atguigu,CompactBuffer(1)), (world,CompactBuffer(1)))
scala> res3.map(t => (t._1, t._2.sum))
res5: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[5] at map at <console>:31
scala> res5.collect
res7: Array[(String, Int)] = Array((are,1), (hello,2), (go,1), (atguigu,1), (world,1))
注意:
基于当前的实现,
groupByKey必须在内存中持有所有的键值对. 如果一个key有太多的value, 则会导致内存溢出(OutOfMemoryError)所以这操作非常耗资源, 如果分组的目的是为了在每个
key上执行聚合操作(比如:sum和average), 则应该使用PairRDDFunctions.aggregateByKey或者PairRDDFunctions.reduceByKey, 因为他们有更好的性能(会先在分区进行预聚合)
4. reduceByKey和groupByKey的区别
reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[k,v]。groupByKey:按照key进行分组,直接进行shuffle。开发指导:r
educeByKey比groupByKey性能更好,建议使用。但是需要注意是否会影响业务逻辑。
5. aggregateByKey(zeroValue)(seqOp, combOp, [numTasks])
函数声明:
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)] = self.withScope {
aggregateByKey(zeroValue, defaultPartitioner(self))(seqOp, combOp)
}
使用给定的 combine 函数和一个初始化的zero value, 对每个key的value进行聚合.
这个函数返回的类型U不同于源 RDD 中的V类型. U的类型是由初始化的zero value来定的. 所以, 我们需要两个操作:
- 一个操作(
seqOp)去把 1 个v变成 1 个U - 另外一个操作(
combOp)来合并 2 个U
第一个操作用于在一个分区进行合并, 第二个操作用在两个分区间进行合并.
为了避免内存分配, 这两个操作函数都允许返回第一个参数, 而不用创建一个新的U
参数描述:
zeroValue:给每一个分区中的每一个key一个初始值;seqOp:函数用于在每一个分区中用初始值逐步迭代value;combOp:函数用于合并每个分区中的结果。
案例:
需求: 创建一个 pairRDD,取出每个分区相同key对应值的最大值,然后相加
案例分析: ppt 分析
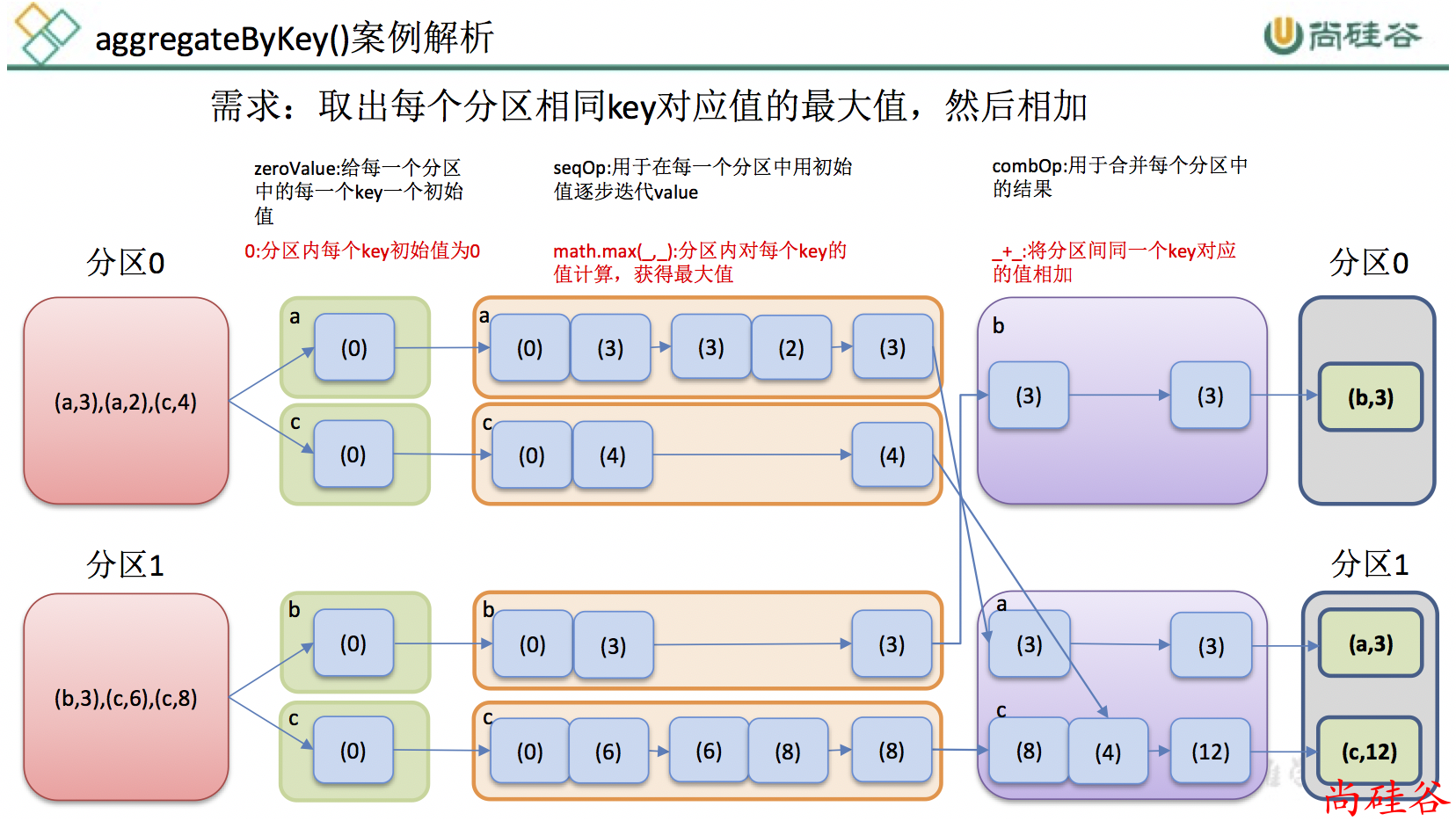
scala> val rdd = sc.parallelize(List(("a",3),("a",2),("c",4),("b",3),("c",6),("c",8)),2)
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd.aggregateByKey(Int.MinValue)(math.max(_, _), _ +_)
res0: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[1] at aggregateByKey at <console>:27
scala> res0.collect
res1: Array[(String, Int)] = Array((b,3), (a,3), (c,12))
练习: 计算每个 key 的平均值
6. foldByKey
参数: (zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
作用:aggregateByKey的简化操作,seqop和combop相同
scala> val rdd = sc.parallelize(Array(("a",3), ("a",2), ("c",4), ("b",3), ("c",6), ("c",8)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[2] at parallelize at <console>:24
scala> rdd.foldByKey(0)(_ + _).collect
res5: Array[(String, Int)] = Array((b,3), (a,5), (c,18))
思考:
workcount可以使用那些算子?思考:
reduceByKey, aggregateByKey, foldByKey的区别和联系?