16.2.2 window 操作
Spark Streaming 也提供了窗口计算, 允许执行转换操作作用在一个窗口内的数据.
默认情况下, 计算只对一个时间段内的RDD进行, 有了窗口之后, 可以把计算应用到一个指定的窗口内的所有 RDD 上.
一个窗口可以包含多个时间段. 基于窗口的操作会在一个比StreamingContext的批次间隔更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。
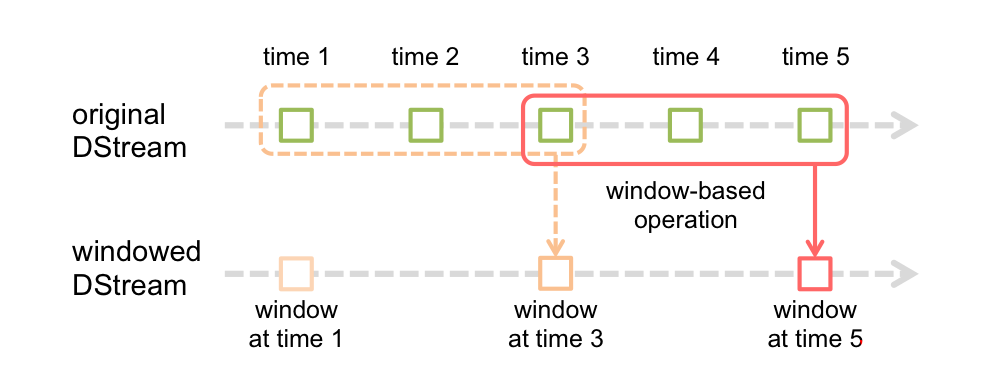
观察上图, 窗口在 DStream 上每滑动一次, 落在窗口内的那些 RDD会结合在一起, 然后在上面操作产生新的 RDD, 组成了 window DStream.
在上面图的情况下, 操作会至少应用在 3 个数据单元上, 每次滑动 2 个时间单位. 所以, 窗口操作需要 2 个参数:
窗口长度 -- 窗口的持久时间(执行一次持续多少个时间单位)(图中是 3)
滑动步长 -- 窗口操作被执行的间隔(每多少个时间单位执行一次).(图中是 2 )
注意: 这两个参数必须是源 DStream 的 interval 的倍数.
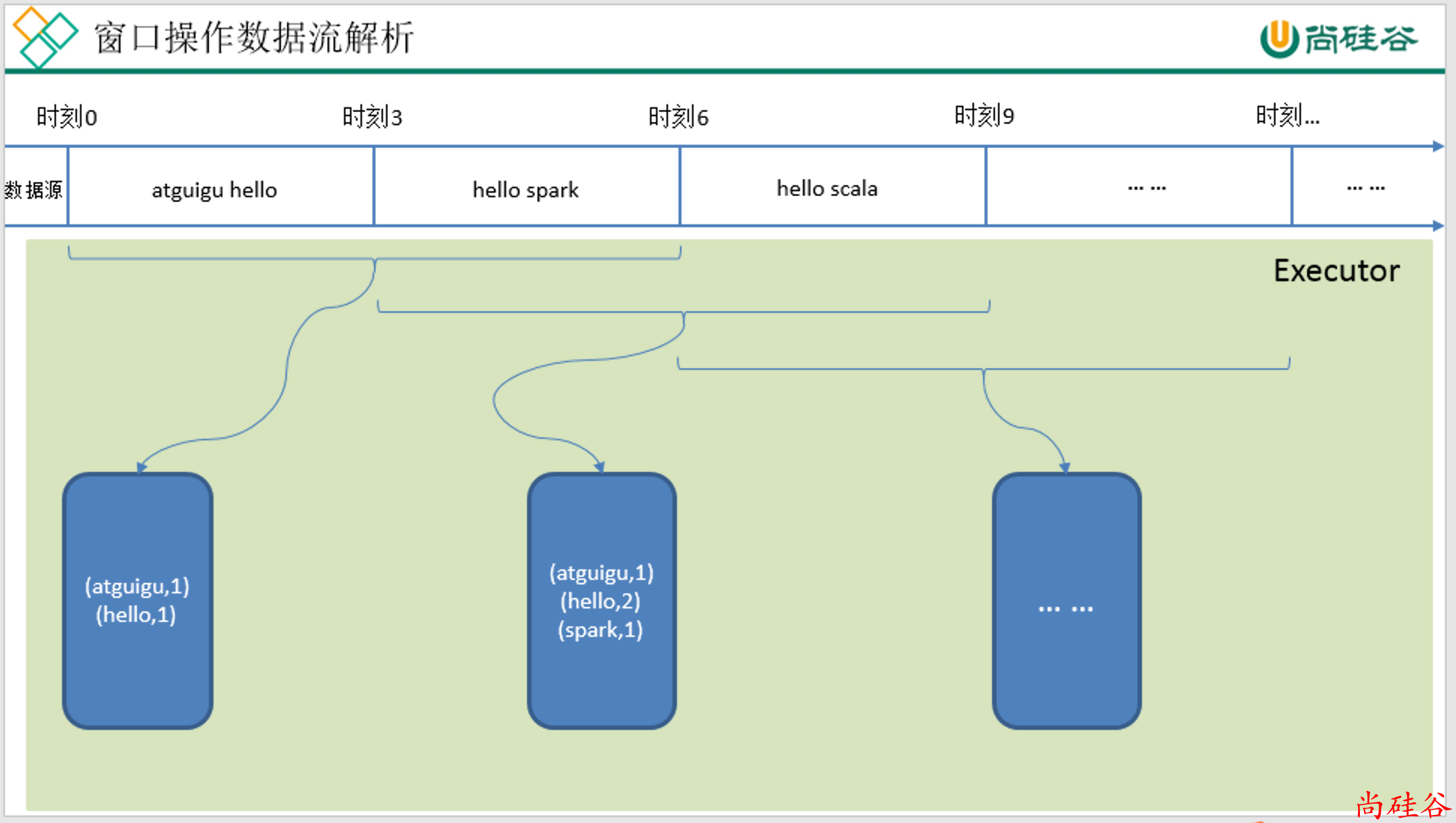
1. reduceByKeyAndWindow(reduceFunc: (V, V) => V, windowDuration: Duration)
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
/*
参数1: reduce 计算规则
参数2: 窗口长度
参数3: 窗口滑动步长. 每隔这么长时间计算一次.
*/
val count: DStream[(String, Int)] =
wordAndOne.reduceByKeyAndWindow((x: Int, y: Int) => x + y,Seconds(15), Seconds(10))

2. reduceByKeyAndWindow(reduceFunc: (V, V) => V, invReduceFunc: (V, V) => V, windowDuration: Duration, slideDuration: Duration)
比没有invReduceFunc高效. 会利用旧值来进行计算.
invReduceFunc: (V, V) => V 窗口移动了, 上一个窗口和新的窗口会有重叠部分, 重叠部分的值可以不用重复计算了. 第一个参数就是新的值, 第二个参数是旧的值.
ssc.sparkContext.setCheckpointDir("hdfs://hadoop201:9000/checkpoint")
val count: DStream[(String, Int)] =
wordAndOne.reduceByKeyAndWindow((x: Int, y: Int) => x + y,(x: Int, y: Int) => x - y,Seconds(15), Seconds(10))
3. window(windowLength, slideInterval)
基于对源 DStream 窗化的批次进行计算返回一个新的 Dstream
4. countByWindow(windowLength, slideInterval)
返回一个滑动窗口计数流中的元素的个数。
5. countByValueAndWindow(windowLength, slideInterval, [numTasks])
对(K,V)对的DStream调用,返回(K,Long)对的新DStream,其中每个key的的对象的v是其在滑动窗口中频率。如上,可配置reduce任务数量。