6.1 堆内核堆外内存规划
Spark 将内存从逻辑上区分为MemoryMode).
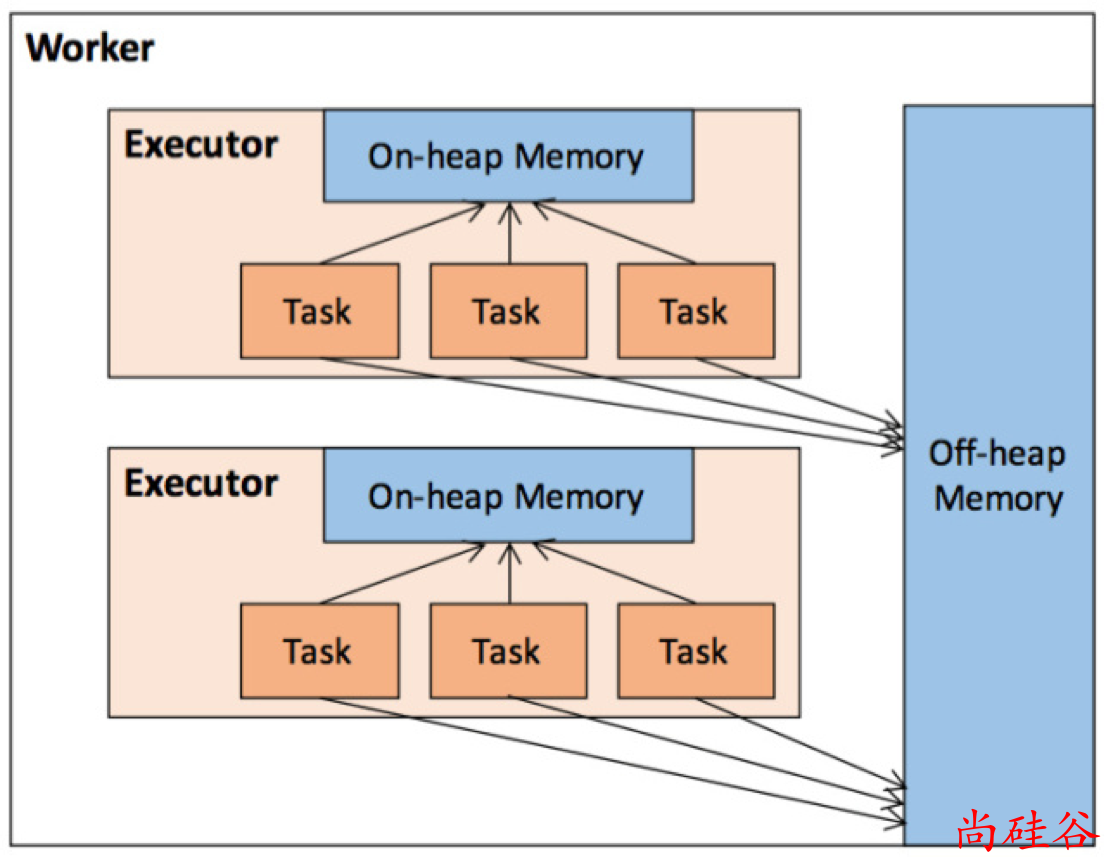
枚举类型MemoryMode中定义了堆内存和堆外内存:
@Private
public enum MemoryMode {
ON_HEAP, // 堆内内存
OFF_HEAP // 堆外内存
}
说明:
这里的堆内存不能与 JVM 中的 Java 堆直接画等号, 它只是 JVM 堆内存的一部分. 由 JVM 统一管理
堆外内存则是 Spark 使用
sun.misc.Unsafe的 API 直接在工作节点的系统内存中开辟的空间.
内存池
无论前面的哪种内存, 都需要一个内存池对内存进行资源管理, 抽象类MemoryPool定义了内存池的规范:
private[memory] abstract class MemoryPool(lock: Object) {
@GuardedBy("lock")
private[this] var _poolSize: Long = 0
/**
* Returns the current size of the pool, in bytes.
*/
final def poolSize: Long = lock.synchronized {
_poolSize
}
/**
* Returns the amount of free memory in the pool, in bytes.
*/
final def memoryFree: Long = lock.synchronized {
_poolSize - memoryUsed
}
/**
* Expands the pool by `delta` bytes.
*/
final def incrementPoolSize(delta: Long): Unit = lock.synchronized {
require(delta >= 0)
_poolSize += delta
}
/**
* Shrinks the pool by `delta` bytes.
*/
final def decrementPoolSize(delta: Long): Unit = lock.synchronized {
require(delta >= 0)
require(delta <= _poolSize)
require(_poolSize - delta >= memoryUsed)
_poolSize -= delta
}
/**
* Returns the amount of used memory in this pool (in bytes).
*/
def memoryUsed: Long
}
有两个实现类:

堆内内存
堆内内存的大小由 Spark 应用程序启动时的-executor-memory 或 spark.executor.memory 参数配置.
Executor内运行的并发任务共享 JVM 堆内内存, 这些任务在缓存 RDD 数据和广播数据时占用的内存被规划为存储内存 而这些任务在执行 Shuffle 时占用的内存被规划为执行内存.
剩余的部分不做特殊规划, 那些 Spark 内部的对象实例, 或者用户定义的 Spark 应用程序中的对象实例, 均占用剩余的空间.
不同的管理模式下, 这三部分占用的空间大小各不相同.
Spark 对堆内内存的管理是一种逻辑上的”规划式”的管理,因为对象实例占用内存的申请和释放都由 JVM 完成,Spark 只能在申请后和释放前记录这些内存,我们来看其具体流程:
申请内存流程如下:
- Spark 在代码中 new 一个对象实例;
- JVM 从堆内内存分配空间,创建对象并返回对象引用;
- Spark 保存该对象的引用,记录该对象占用的内存。
释放内存流程如下
- Spark记录该对象释放的内存,删除该对象的引用;
- 等待JVM的垃圾回收机制释放该对象占用的堆内内存。
存在的问题
我们知道,JVM 的对象可以以序列化的方式存储,序列化的过程是将对象转换为二进制字节流,本质上可以理解为将非连续空间的链式存储转化为连续空间或块存储,在访问时则需要进行序列化的逆过程——反序列化,将字节流转化为对象,
序列化的方式可以节省存储空间,但增加了存储和读取时候的计算开销。 对于 Spark 中序列化的对象,由于是字节流的形式,其占用的内存大小可直接计算,而对于非序列化的对象,其占用的内存是通过周期性地采样近似估算而得,即并不是每次新增的数据项都会计算一次占用的内存大小,这种方法降低了时间开销但是有可能误差较大,导致某一时刻的实际内存有可能远远超出预期。
此外,在被 Spark 标记为释放的对象实例,很有可能在实际上并没有被 JVM 回收,导致实际可用的内存小于 Spark 记录的可用内存。所以 Spark 并不能准确记录实际可用的堆内内存,从而也就无法完全避免内存溢出(OOM, Out of Memory)的异常。
虽然不能精准控制堆内内存的申请和释放,但 Spark 通过对存储内存和执行内存各自独立的规划管理,可以决定是否要在存储内存里缓存新的 RDD,以及是否为新的任务分配执行内存,在一定程度上可以提升内存的利用率,减少异常的出现。
堆外内存
为了进一步优化内存的使用以及提高 Shuffle 时排序的效率,Spark 引入了堆外(Off-heap)内存,使之可以
堆外内存意味着把内存对象分配在 Java 虚拟机的堆以外的内存,这些内存
利用 JDK Unsafe API,Spark 可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的 GC 扫描和回收,提升了处理性能。
堆外内存可以被精确地申请和释放(堆外内存之所以能够被精确的申请和释放,是由于内存的申请和释放不再通过JVM机制,而是直接向操作系统申请,JVM对于内存的清理是无法准确指定时间点的,因此无法实现精确的释放),而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。
在默认情况下堆外内存并不启用,可通过配置 spark.memory.offHeap.enabled 参数启用,并由 spark.memory.offHeap.size 参数设定堆外空间的大小。
除了没有 other 空间,堆外内存与堆内内存的划分方式相同,