5.3 SortShuffle 解析
5.3.1 普通 SortShuffle
在该模式下,数据会先写入一个数据结构,reduceByKey 写入 Map,一边通过 Map 局部聚合,一遍写入内存。Join 算子写入 ArrayList 直接写入内存中。然后需要判断是否达到阈值,如果达到就会将内存数据结构的数据写入到磁盘,清空内存数据结构。
在溢写磁盘前,先根据 key 进行排序,排序过后的数据,会分批写入到磁盘文件中。默认批次为 10000 条,数据会以每批一万条写入到磁盘文件。写入磁盘文件通过缓冲区溢写的方式,每次溢写都会产生一个磁盘文件,也就是说一个 Task 过程会产生多个临时文件。
最后在每个 Task 中,将所有的临时文件合并,这就是merge过程,此过程将所有临时文件读取出来,一次写入到最终文件。意味着一个Task的所有数据都在这一个文件中。同时单独写一份索引文件,标识下游各个Task的数据在文件中的索引,start offset和end offset。
5.3.2 bypass SortShuffle
bypass运行机制的触发条件如下(必须同时满足):
- shuffle map task数量小于
spark.shuffle.sort.bypassMergeThreshold参数的值,默认为200。 - 不是聚合类的
shuffle算子(比如reduceByKey)。
此时 task 会为每个 reduce 端的 task 都创建一个临时磁盘文件,并将数据按 key 进行 hash 然后根据key 的 hash 值,将 key 写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
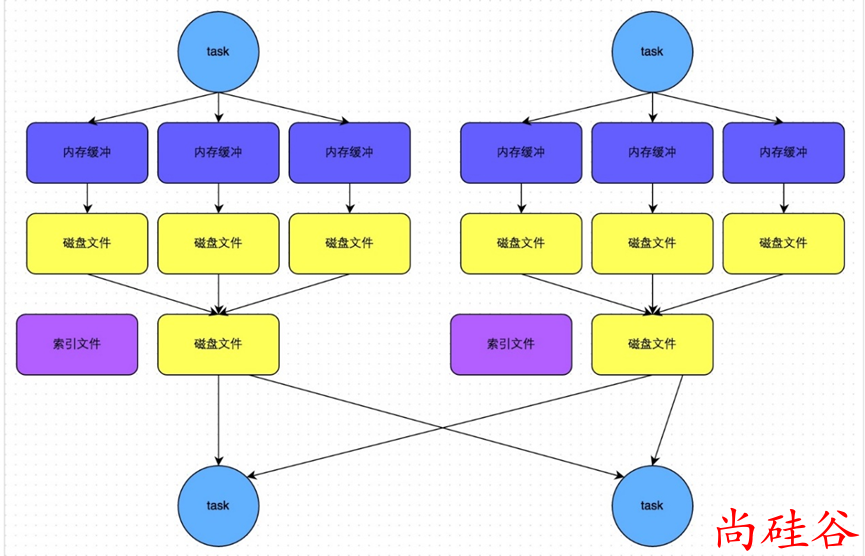
该过程的磁盘写机制其实跟未经优化的 HashShuffleManager 是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,shuffle read的性能会更好。
而该机制与普通SortShuffleManager运行机制的不同在于:不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。