4.2 Spark Stage 级别调度
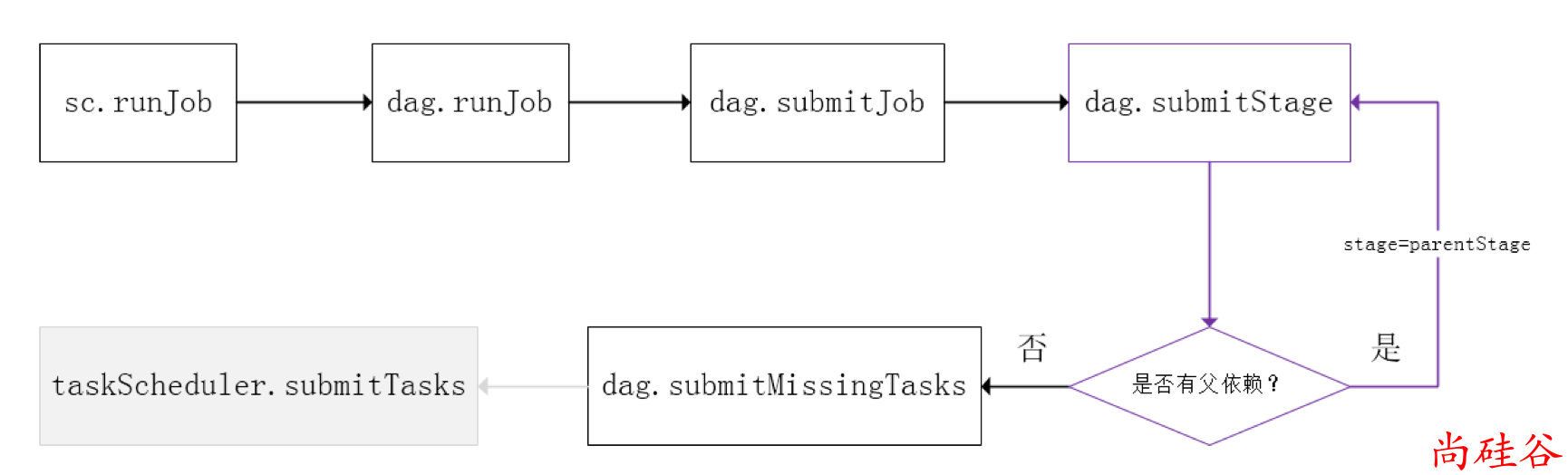
Spark的任务调度是从DAG切割开始,主要是由DAGScheduler来完成。当遇到一个Action操作后就会触发一个Job的计算,并交给DAGScheduler来提交,下图是涉及到Job提交的相关方法调用流程图。
Job 由最终的
RDD和Action方法封装而成;SparkContext将Job交给DAGScheduler提交,它会根据RDD的血缘关系构成的DAG进行切分,将一个Job划分为若干Stages,具体划分策略是,由最终的RDD不断通过依赖回溯判断父依赖是否是宽依赖,即以Shuffle为界,划分Stage,窄依赖的RDD之间被划分到同一个Stage中,可以进行pipeline式的计算。划分的
Stages分两类,一类叫做ResultStage,为DAG最下游的Stage,由Action方法决定,另一类叫做ShuffleMapStage,为下游Stage准备数据
下面看一个简单的例子
WordCount。

说明:
Job由saveAsTextFile触发,该Job由RDD-3和saveAsTextFile方法组成,根据RDD之间的依赖关系从RDD-3开始回溯搜索,直到没有依赖的RDD-0,在回溯搜索过程中,
RDD-3依赖RDD-2,并且是宽依赖,所以在RDD-2和RDD-3之间划分Stage,RDD-3被划到最后一个Stage,即ResultStage中RDD-2依赖RDD-1,RDD-1依赖RDD-0,这些依赖都是窄依赖,所以将RDD-0、RDD-1和RDD-2划分到同一个Stage,即ShuffleMapStage中,实际执行的时候,数据记录会一气呵成地执行RDD-0到RDD-2的转化。不难看出,其本质上是一个深度优先搜索算法。
一个Stage是否被提交,需要判断它的父Stage是否执行,只有在父Stage执行完毕才能提交当前Stage
如果一个Stage没有父Stage,那么从该Stage开始提交。
Stage提交时会将Task信息(分区信息以及方法等)序列化并被打包成TaskSet交给TaskScheduler,一个Partition对应一个Task,另一方面TaskScheduler会监控Stage的运行状态,只有Executor丢失或者Task由于Fetch失败才需要重新提交失败的Stage以调度运行失败的任务,其他类型的Task失败会在TaskScheduler的调度过程中重试。
相对来说DAGScheduler做的事情较为简单,仅仅是在Stage层面上划分DAG,提交Stage并监控相关状态信息。
TaskScheduler则相对较为复杂,下面详细阐述其细节。