4.3.1 调度策略
TaskScheduler支持两种调度策略,一种是FIFO,也是默认的调度策略,另一种是FAIR。
在TaskScheduler初始化过程中会实例化rootPool,表示树的根节点,是Pool类型。
FIFO调度策略
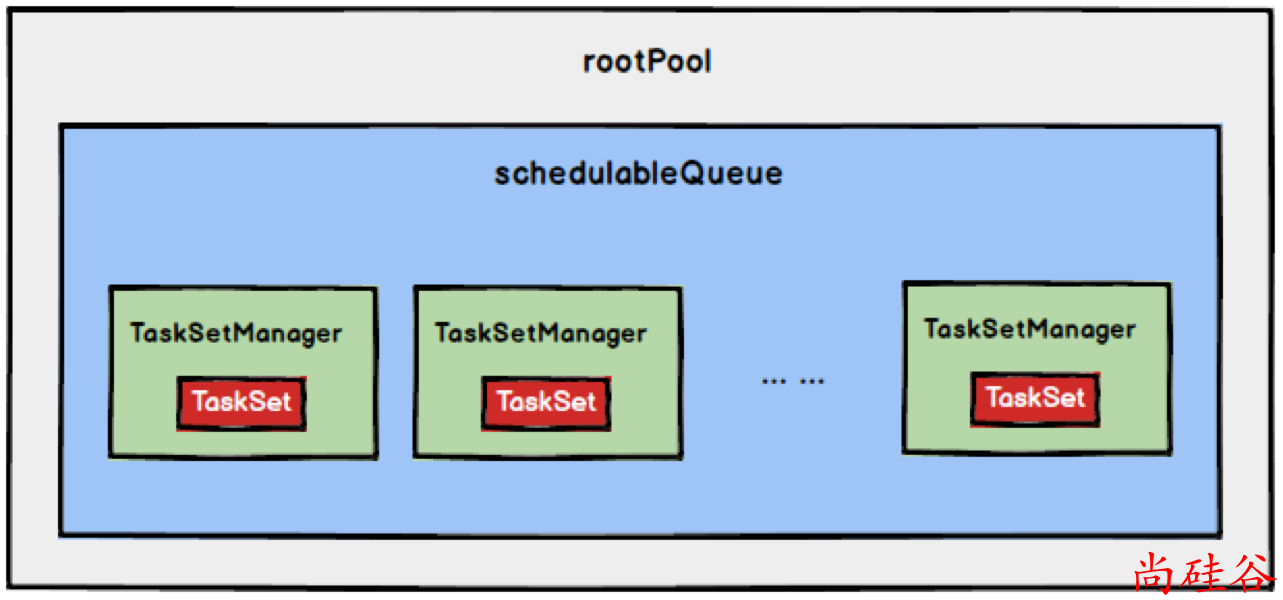
如果是采用FIFO调度策略,则直接简单地将TaskSetManager按照先来先到的方式入队,出队时直接拿出最先进队的TaskSetManager,其树结构如下图所示,TaskSetManager保存在一个FIFO队列中。
FAIR调度策略(0.8 开始支持)
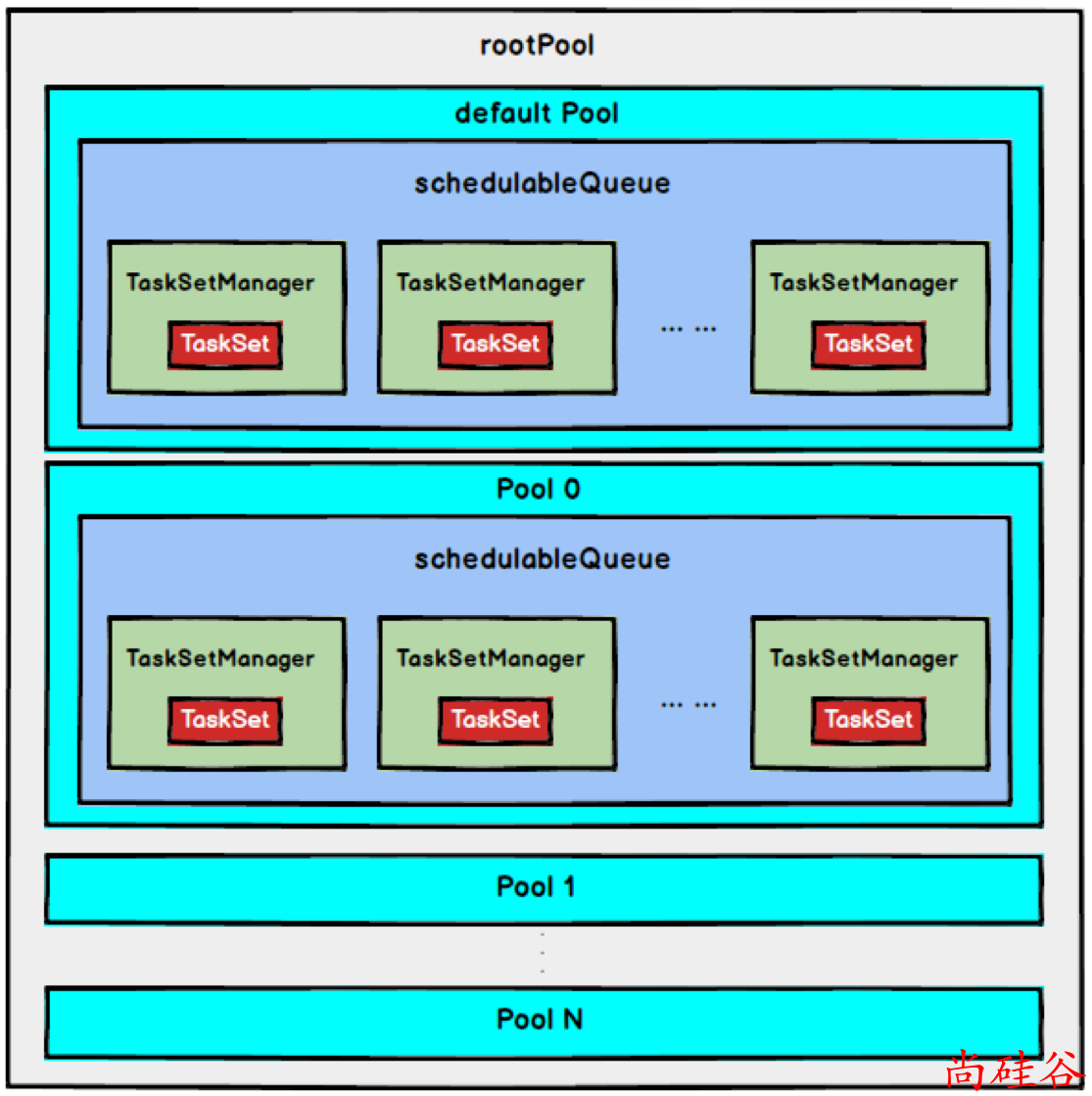
FAIR模式中有一个rootPool和多个子Pool,各个子Pool中存储着所有待分配的TaskSetMagager。
在FAIR模式中,需要先对子Pool进行排序,再对子Pool里面的TaskSetMagager进行排序,因为Pool和TaskSetMagager都继承了Schedulable特质,因此使用相同的排序算法。
排序过程的比较是基于Fair-share来比较的,每个要排序的对象包含三个属性: runningTasks值(正在运行的Task数)、minShare值、weight值,比较时会综合考量runningTasks值,minShare值以及weight值。
如果 A 对象的
runningTasks大于它的minShare,B 对象的runningTasks小于它的minShare,那么B排在A前面;(runningTasks 比 minShare 小的先执行) 如果A、B对象的
runningTasks都小于它们的minShare,那么就比较runningTasks与math.max(minShare1, 1.0)的比值(minShare使用率),谁小谁排前面;(minShare使用率低的先执行) 如果A、B对象的
runningTasks都大于它们的minShare,那么就比较runningTasks与weight的比值(权重使用率),谁小谁排前面。(权重使用率低的先执行) 如果上述比较均相等,则比较名字。
FAIR模式排序完成后,所有的TaskSetManager被放入一个ArrayBuffer里,之后依次被取出并发送给Executor执行。
从调度队列中拿到TaskSetManager后,由于TaskSetManager封装了一个Stage的所有Task,并负责管理调度这些Task,那么接下来的工作就是TaskSetManager按照一定的规则一个个取出Task给TaskScheduler,TaskScheduler再交给SchedulerBackend去发到Executor上执行。
如何启用公平调度器:
val conf = new SparkConf().setMaster(...).setAppName(...)
conf.set("spark.scheduler.mode", "FAIR")
val sc = new SparkContext(conf)