4.1 Spark 任务调度概述
当 Driver 起来后,Driver 则会根据用户程序逻辑准备任务,并根据Executor资源情况逐步分发任务。
在详细阐述任务调度前,首先说明下 Spark 里的几个概念。一个 Spark 应用程序包括Job、Stage以及Task三个概念:
Job 是以
Action算子为界,遇到一个Action算子则触发一个Job;Stage 是 Job 的子集,以 RDD 宽依赖(即 Shuffle )为界,遇到 Shuffle 做一次划分;
Task 是 Stage 的子集,以并行度(分区数)来衡量,这个 Stage 分区数是多少,则这个Stage 就有多少个 Task。
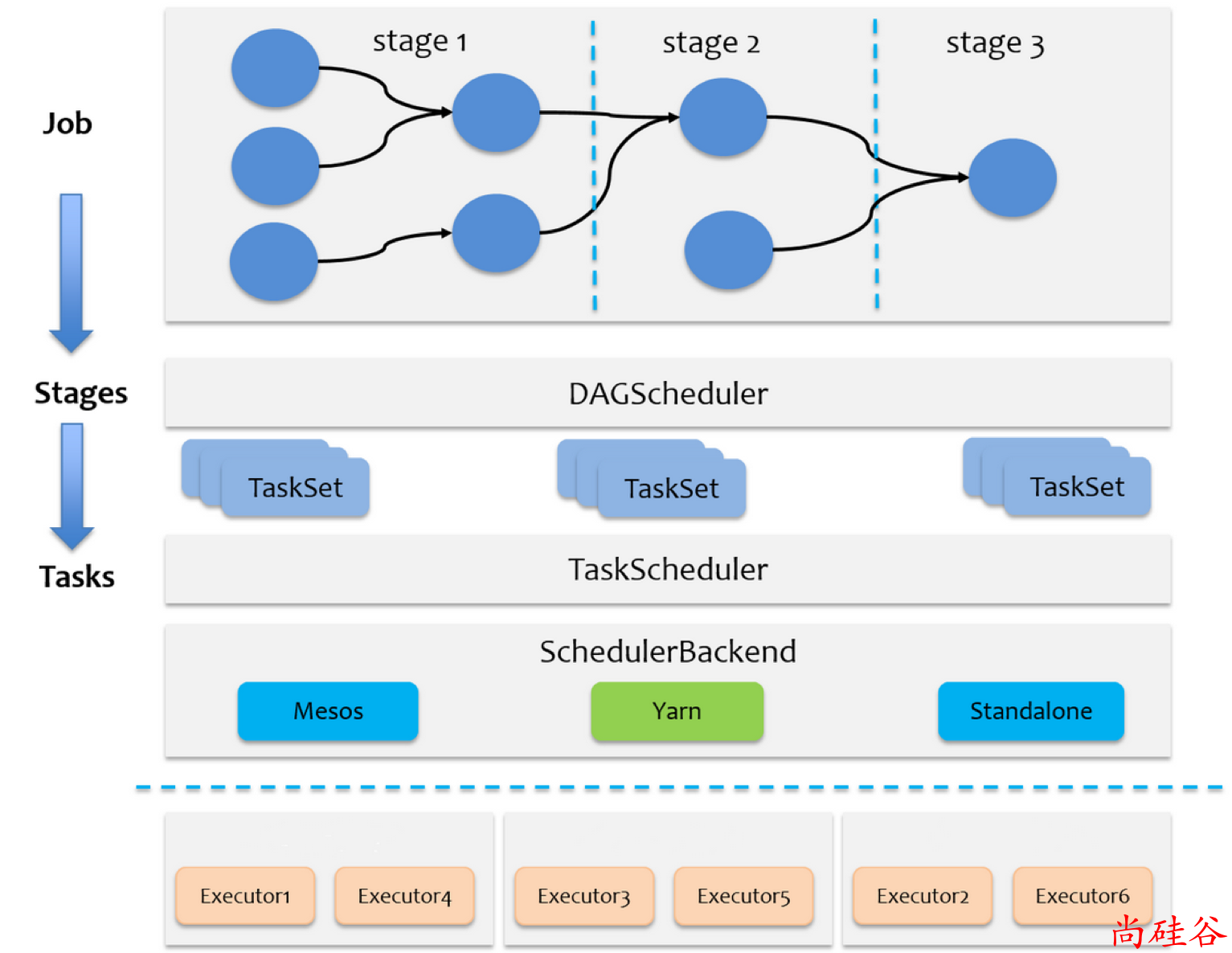
Spark RDD 通过其 Transactions 操作,形成了RDD血缘关系图,即DAG,最后通过Action的调用,触发Job并调度执行。
DAGScheduler负责Stage级的调度,主要是将job切分成若干Stages,并将每个Stage打包成TaskSet交给TaskScheduler调度。
TaskScheduler负责Task级的调度,将DAGScheduler传过来的TaskSet按照指定的调度策略分发到Executor上执行,调度过程中SchedulerBackend负责提供可用资源,其中SchedulerBackend有多种实现,分别对接不同的资源管理系统。
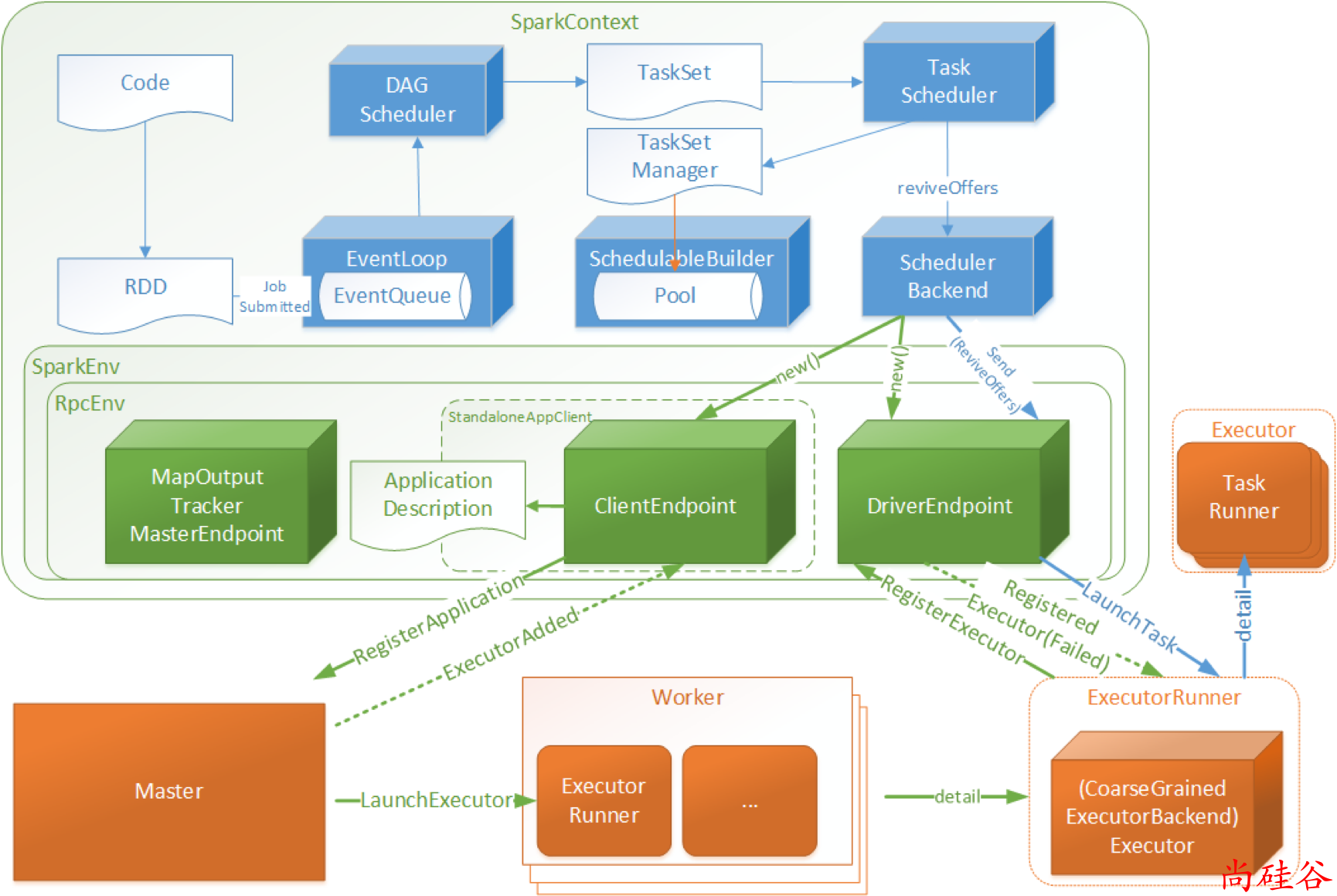
Driver初始化SparkContext过程中,会分别初始化DAGScheduler、TaskScheduler、SchedulerBackend以及HeartbeatReceiver,并启动 SchedulerBackend以及HeartbeatReceiver。
SchedulerBackend通过ApplicationMaster申请资源,并不断从TaskScheduler中拿到合适的Task分发到Executor执行。
HeartbeatReceiver负责接收Executor的心跳信息,监控Executor的存活状况,并通知到TaskScheduler。