5.1 Shuffle 的核心要点
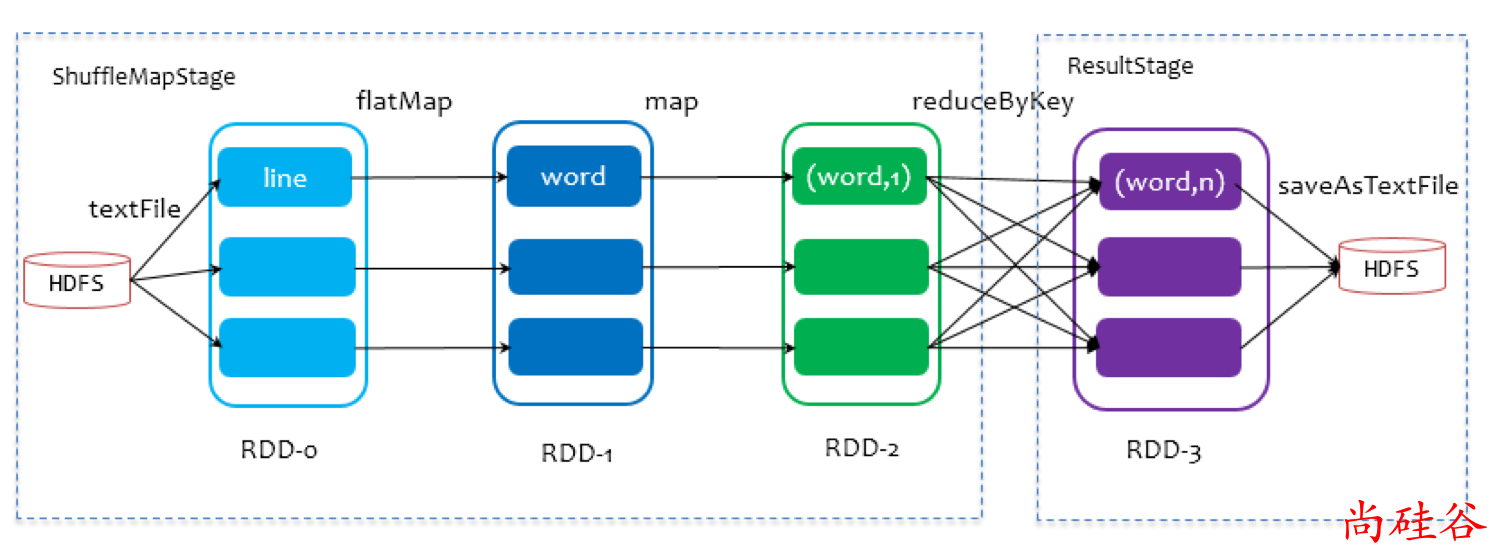
在划分 Stage 时,最后一个 Stage 称为finalStage(变量名),它本质上是一个ResultStage类型的对象,前面的所有 Stage 被称为 ShuffleMapStage。
ShuffleMapStage 的结束伴随着 shuffle 文件的写磁盘。
ResultStage 基本上对应代码中的 action 算子,即将一个函数应用在 RDD的各个partition的数据集上,意味着一个job的运行结束。
5.1.1 Shuffle 流程源码分析
我们从CoarseGrainedExecutorBackend开始分析
启动任务
override def receive: PartialFunction[Any, Unit] = {
case LaunchTask(data) =>
if (executor == null) {
} else {
val taskDesc = ser.deserialize[TaskDescription](data.value)
// 启动任务
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
}
}
Executor.launchTask方法
def launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer): Unit = {
// Runnable 接口的对象.
val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,
serializedTask)
runningTasks.put(taskId, tr)
// 在线程池中执行 task
threadPool.execute(tr)
}
tr.run方法
override def run(): Unit = {
// 更新 task 的状态
execBackend.statusUpdate(taskId, TaskState.RUNNING, EMPTY_BYTE_BUFFER)
try {
// 把任务相关的数据反序列化出来
val (taskFiles, taskJars, taskProps, taskBytes) =
Task.deserializeWithDependencies(serializedTask)
val value = try {
// 开始运行 Task
val res = task.run(
taskAttemptId = taskId,
attemptNumber = attemptNumber,
metricsSystem = env.metricsSystem)
res
} finally {
}
} catch {
} finally {
}
}
Task.run方法
final def run(
taskAttemptId: Long,
attemptNumber: Int,
metricsSystem: MetricsSystem): T = {
context = new TaskContextImpl(
stageId,
partitionId,
taskAttemptId,
attemptNumber,
taskMemoryManager,
localProperties,
metricsSystem,
metrics)
try {
// 运行任务
runTask(context)
} catch {
} finally {
}
}
Task.runTask方法
Task.runTask是一个抽象方法.
Task 有两个实现类, 分别执行不同阶段的Task
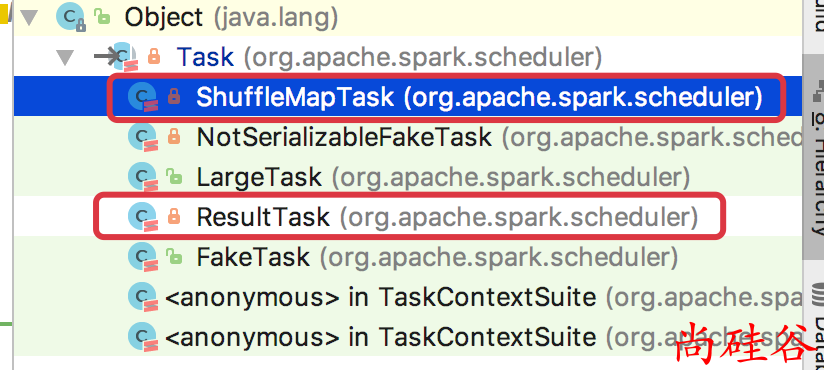
ShuffleMapTask源码分析
ShuffleMapTask.runTask方法
override def runTask(context: TaskContext): MapStatus = {
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
// 获取 ShuffleWriter
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
// 写出 RDD 中的数据. rdd.iterator 是读(计算)数据的操作.
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
} catch {
}
}
具体如何把数据写入到磁盘, 是由ShuffleWriter.write方法来完成.
ShuffleWriter是一个抽象类, 有 3 个实现:
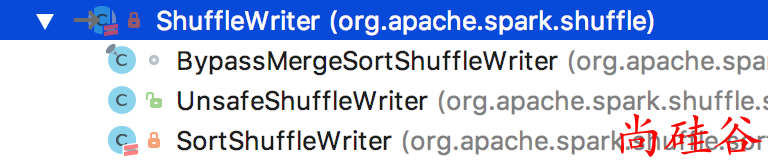
根据在manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)中的dep.shuffleHandle由manager来决定选使用哪种ShuffleWriter.
ShuffleManager
ShuffleManage 是一个Trait, 从2.0.0开始就只有一个实现类了: SortShuffleManager
registerShuffle方法: 匹配出来使用哪种ShuffleHandle
override def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle = {
if (SortShuffleWriter.shouldBypassMergeSort(SparkEnv.get.conf, dependency)) {
new BypassMergeSortShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else if (SortShuffleManager.canUseSerializedShuffle(dependency)) {
new SerializedShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else {
new BaseShuffleHandle(shuffleId, numMaps, dependency)
}
}
getWriter方法
/** Get a writer for a given partition. Called on executors by map tasks. */
override def getWriter[K, V](
handle: ShuffleHandle,
mapId: Int,
context: TaskContext): ShuffleWriter[K, V] = {
// 根据不同的 Handle, 创建不同的 ShuffleWriter
handle match {
case unsafeShuffleHandle: SerializedShuffleHandle[K@unchecked, V@unchecked] =>
new UnsafeShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
context.taskMemoryManager(),
unsafeShuffleHandle,
mapId,
context,
env.conf)
case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K@unchecked, V@unchecked] =>
new BypassMergeSortShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
bypassMergeSortHandle,
mapId,
context,
env.conf)
case other: BaseShuffleHandle[K@unchecked, V@unchecked, _] =>
new SortShuffleWriter(shuffleBlockResolver, other, mapId, context)
}
}